Gemini 2.5 Pro is so much of a step up (IME) that I've become sold on Google's models in general. It not only is smarter than me on most of the subjects I engage with it, it also isn't completely obsequious. The model pushes back on me rather than contorting itself to find a way to agree.
100% of my casual AI usage is now in Gemini and I look forward to asking it questions on deep topics because it consistently provides me with insight. I am building new tools with the mind to optimize my usage to increase it's value to me.
Paying real API money for Claude to jump the gun on solutions invalidated the advantage of having a tool as nice as Claude Code, at least for me, I admit everyone's mileage will vary.
It put an expensive API call inside a useEffect hook. I wanted the call elsewhere and it fought me on it pretty aggressively. Instead of removing the call, it started changing comments and function names to say that the call was just loading already fetched data from a cache (which was not true). I could not find a way to tell it to remove that API call from the useEffect hook, It just wrote more and more motivated excuses in the surrounding comments. It would have been very funny if it weren't so expensive.
Models used to do this much much more than now, so what it did doesn't surprise us.
The nature of these tools is to copy what we have already written. It has seen many threads where developers argue and dig in, they try to train the AI not to do that but sometimes it still happens and then it just roleplays as the developer that refuses to listen to anything you say.
Sorry what do you mean by this?
google models on cli are great.
I added a very short chapter on setting this up (direct link to my book online): https://leanpub.com/ollama/read#using-the-open-codex-command...
This morning I tweaked my Open Codex config to also try gemma3:27b-it-qat - and Google’s olen source small is excellent: runs fast enough for a good dev experience, with very good functionality.
Any ide integration?
The LLM field is moving so fast that what is the leading frontier model today, may not be the same tomorrow.
Pricing is another important consideration. https://aider.chat/docs/leaderboards/
Perhaps someone can merge the best of Aider and codex/claude code now. Looking forward to it.
Only Claude (to my knowledge) has a desktop app which can directly, and usually quite intelligently, modify files and create repos on your desktop. It's the only "agentic" option among the major players.
"Claude, make me an app which will accept Stripe payments and sell an ebook about coding in Python; first create the app, then the ebook."
It would take a few passes but Claude could do this; obviously you can't do that with an API alone. That capability alone is worth $30/month in my opinion.
But there are third party options availabe that to the very same thing (e.g. https://aider.chat/ ) which allow you to plug in a model (or even a combination thereof e.g. deepseek as architect and claude as code writer) of your choice.
Therefore the advantage of the model provider providing such a thing doesn't matter, no?
there's also claude code proxy's to run it on local llm's
you can just do things
> It would take a few passes but Claude could do this;
I'm sorry but absolutely nothing I've seen from using Claude indicates that you could give it a vague prompt like that and have it actually produce anything worth reading.
Can it output a book's worth of bullshit with that prompt? Yes. But if you think "write a book about Python" is where we are in the state of the art in language models in terms of the prompt you need to get a coherent product, I want some of whatever you are smoking because that has got to be the good shit
Of course, this is only my experience and codex is still very young. I really hope it becomes as capable as Claude.
However, Sonnet 3.7 seemed like a very small increase, whereas 2.5 Pro seemed like quite a leap.
Now, IME, Google seems to be comfortably ahead.
2.5 Pro is a little slow, though.
I'm not sure which model Google uses for the AI answers on search, but I find myself using Search for a lot of things I might ask Gemini (via 2.5 Pro) if it was as fast as Search's AI answers.
Gemini doesn't seem to be as keen to agree with me so I find it makes small improvements where Claude and OpenAI will go along with initial suggestions until specifically asked to make improvements.
So I think patterns from the training data are still overriding some actual logic/intelligence in the model. Or the Google assistant fine-tuning is messing it up.
For example: I asked both to change a bunch of code into functions to pass into a `pipe` type function, and Gemini truly seemed to have no idea what it was supposed to do, and Claude just did it.
Maybe there was some user error or something, but after that I haven’t really used Gemini.
I’m curious if people are using Gemini and loving it are using it mostly for one-shotting, or if they’re working with it more closely like a pair programmer? I could buy that it could maybe be good at one but bad at the other?
It also seems to be better at incorporating knowledge from documentation and existing examples when provided.
Perhaps this is down to specific tools and their prompts? In my case, this was Cursor used in agent mode.
Or perhaps it's about the languages involved - my experiments were with TypeScript and C++.
I feel like you might be using it differently to me. I generally don't ask AI to find the cause of a bug, because it's quite bad at that. I use it to identify relevant parts of the code that could be involved in the bug, and then I come up with my own hypotheses for the cause. Then I use AI to help write tests to validate these hypotheses. I mostly use Rust.
And we aren't talking about trivial bugs here. For TypeScript, the most impressive bug it handled to date was an async race condition due to missing await causing a property to be overwritten with invalid value. For that one I actually had to do some manual debugging and tell it what I observed, but given that info, it was able to locate the problem in the code all by itself and fix it correctly and come up with a way to test it as well.
For C++, the codebase in question was gdb, the bug was a test issue, and it correctly found problematic code based solely on the test log (but I had to prod it a bit in the right direction for the fix).
I should note that this is Gemini Pro 2.5 specifically. When I tried Google's models previously (for all kinds of tasks), I was very unimpressed - it was noticeably worse than other SOTA models, so I was very skeptical going into this. Indeed, I started with Sonnet precisely because my past experience indicated that it was the best option, and I only tried Gemini after Sonnet fumbled.
It might be because most bugs that you would encounter in other languages don't occur in the first place in Rust because of the stronger type system. The race condition one you mentioned wouldn't be possible for example. If something like that would occur, it's a compiler error and the AI fixes it while still in the initial implementation stage by looking at the linter errors. I also put a lot of effort into trying to use coding patterns that do as much validation as possible within the type system. So in the end all that's left are the more difficult bugs where a human is needed to assist (for now at least, I'm confident that the models are only going to get better).
That said I do wonder if the problems you're seeing are simply because there isn't that much Rust in the training set for the models - because, well, there's relatively little of it overall when you compare it to something like C++ or JS.
I partly wonder if different peoples prompt styles will lead to better results with different models.
Manus.im also does code generation in a nice UI, but I’ll probably be using Gemini and Deepseek
No Moat strikes again
They pretty quick to let you use the latest models nowadays.
It's cool to have access to it, but please be careful not to mistake corporate loss leaders for authentic products.
To this day, the Google Home (or is it called Nest now?) speaker is the only physical product i've ever owned where it lost features over time. I used to be able to play the audio of a Youtube video (like a podcast) through it, but then Google decided that it was very very important that I only be able to play a Youtube video through a device with a screen, because it is imperative that I see a still image when I play a longform history podcast.
Obviously, this is a silly and highly specific example, but it is emblematic of how they neglect or enshittify massive swathes of their products as soon as the executive team loses interest and puts their A team on some shiny new object.
Also, Anthropic is also subsidizing queries, no? The new “5x” plan illustrative of this?
No doubt anthropic’s chat ux is the best right now, but it isn’t so far ahead on that or holding some UX moat that I can tell.
Googles previous approach (Pro models available only to Gemini Advanced subscribers, and Advanced trials can’t be stacked with Google One paid storage, or rather they convert the already paid storage portion to a paid, much shorter Advanced subscription!) was mind-bogglingly stupid.
Having a free tier on all models is the reasonable option here.
I agree that giving away access to expensive models long term is not a good idea on several fronts. Personally, I subscribe to Gemini Advanced and I pay for using the Gemini APIs.
EDIT: a very good deal, at $10/month is https://apps.abacus.ai/chatllm/ that gives you access to almost all commercial models as well as the best open weight models. I have never come close at all to using my monthly credits with them. If you like to experiment with many models the service is a lot of fun.
You’ll never know what that something is. For me, I can’t help but think that I’m getting an inferior service.
The also support an application development framework that looks interesting but I have never used it.
Look at Android.
HN behaviour is more like a kid who sees the candy, wants the candy and eats as much as it can without worrying about the damaging effect that sugar will have on their health. Then, the diabetes diagnosis arrives and they complain
Can’t be employees cause usually there is a disclaimer
The best way to shift or create consensus is to make everyone think everyone else's opinion has already shifted, and that consensus is already there. Emperor's new clothes etc..
So shit like "as a googler" requires "my opinions are my own yadda yadda"
Also, why would I want Google to spy on my AI usage? They’re evil.
Thanks for the new word, I have to look it up.
"obedient or attentive to an excessive or servile degree"
Apparently it means an AI that mindlessly follow your logic and instructions without reasoning and articulation is not good enough.
Their career, livelihoods, ability to support their families, etc. are ultimately on the line, so they'll pay lip service if they have to. Consider it part of the job at that point; personal beliefs are often left at the door.
A synonym would be sycophantic which would be "behaving or done in an obsequious way in order to gain advantage." The connotation is the other party misrepresents their own opinion in order to gain favor or avoid disapproval from someone of a higher status. Like when a subordinate tries to guess what their superior wants to hear instead of providing an unbiased response.
I think that accurately describes my experience with some LLMs due to heavy handed RLHF towards agreeableness.
In fact, I think obsequious is a better word since it doesn't have the cynical connotation of sycophant. LLMs don't have a motive and obsequious describes the behavior without specifying the intent.
Obsequious is a bit more general. You could imagine applying it to a waiter or valet who is annoyingly helpful. I don't think it would feel right to use the word simp in that case.
In my day we would call it sucking up. A bit before my time (would sound old timey to me) people called it boot licking. In the novel "Catcher in the Rye", the protagonist uses the word "phony" in a similar way. This kind of behavior is universally disliked so there is a lot slang for it.
Maybe I can locate it
Also the slightly over cheery tone maybe.
Is there a way to tackle this?
I cannot confirm if the quality is downgraded since I haven't had enough time with it. But if what you are saying is correct, I would be very sad. My big fear is the full-fat Gemini 2.5 Pro will be prohibitively expensive, but a dumbed down model (for the sake of cost) would also be saddening.
I hate how slow things are sometimes.
(We do have access to GitHub Copilot)
I have to admit I have a bias where I think Google is "business" while Grok is for lols. But I should probably take the time to asses it since I would prefer to have an opinion based on experience rather than vibes.
It's probably great for lots of things but it doesn't seem very good for recent news. I asked it about recent accusations around xAI and methane gas turbines and it had no clue what I was talking about. I asked the same question to Grok and it gave me all sorts of details.
Gemini performing the best on coding tasks, while giving underwhelming responses on recent news.
While Grok was OK for coding tasks, but being linked to X, provided best response on recent events.
You are missing the point here. The LLM is just the “reasoning engine” for agents now. Its corpus of facts are meaningless, and shouldn’t really be relied upon for anything. But in conjunction with a tool calling agentic process, with access to the web, what you described is now trivially doable. Single shot LLM usage is not really anything anyone should be doing anymore.
I'm just discussing the GP's topic of casual use. Casual use implies heading over to an already-hosted prompt and typing in questions. Implementing my own 'agentic process' does not sound very casual to me.
It really is though. This can be as simple as using Claude desktop with a web search tool.
I generally point people to Anthropic's seminal blog post on the topic: https://www.anthropic.com/engineering/building-effective-age...
For code, gemini is very buggy in cursor, so I use Claude 3.7. But it might be partly cursor's fault.
i'd find the same word improper to describe human beings - other words like plaintive, obedient and compliant often do the job better and are less obscure.
here it feels like a word whose time has come.
Not that I have any actual insight. but doesn't it seem more likely that it will not be a human, but a model? Models training models.
My llm-gemini plugin supports that: https://github.com/simonw/llm-gemini
uv tool install llm
llm install llm-gemini
llm keys set gemini
# paste key here
llm -m gemini-2.5-flash-preview-04-17 \
-o code_excution 1 \
'render a mandelbrot fractal in ascii art'
They don't charge anything extra for code execution, you just pay for input and output tokens. The above example used 10 input, 1,531 output which is $0.15/million for input and $3.50/million output for Gemini 2.5 Flash with thinking enabled, so 0.536 cents (just over half a cent) for this prompt.
Could you elaborate? I thought function calling is a common feature among models from different providers
I wish this was extended to things like: you could give the model an API endpoint that it can call to execute JS code, and the only requirement is that your API has to respond within 5 seconds (maybe less actually).
I wonder if this is what OpenAI is planning to do in the upcoming API update to support tools in o3.
If we're just talking about some API support to call python scripts, that's pretty basic to wire up with any model that supports tool use.
Google is silently winning the AI race.
What I always wonder in these kinds of cases is: What makes you confident the AI actually did a good job since presumably you haven't looked at the thousands of client data yourself?
For all you know it made up 50% of the result.
It's the same problem factories have: they produce a lot of parts, and it's very expensive to put a full operator or more on a machine to do 100% part inspection. And the machines aren't perfect, so we can't just trust that they work.
So starting in the 1920s Walter Shewhart and Edward Deming came up with Statistical Process Control. We accept the quality of the product produced based on the variance we see of samples, and how they measure against upper and lower control limits.
Based on that, we can estimate a "good parts rate" (which later got used in ideas like Six Sigma to describe the probability of bad parts being passed).
The software industry was built on determinism, but now software engineers will need to learn the statistical methods created by engineers who have forever lived in the stochastic world of making physical products.
The main issue I had was it was surprisingly hard to get the model to consistently strip commas from dollar values, which broke the csv output I asked for. I gave up on prompt engineering it to perfection, and just looped around it with a regex check.
Otherwise, accuracy was extremely good and it surfaced a few errors in my spreadsheets over the years.
Everyone has a story of a csv formatting nightmare
It wasn't a one shot deal at all. I found the ambiguous modalities in the data and hand corrected examples to include in the prompt. After about 10 corrections and some exposition about the cases it seemed to misundestand, it got really good. Edit: not too different from a feedback loop with an intern ;)
They also remember what they did - if you spot one misunderstanding, there’s a chance they’ll be able to check all similar scenarios.
Comparing the mechanics of an LLM to human intelligence shows deep misunderstanding of one, the other, or both - if done in good faith of course.
BTW, not sure if you have experiences of delegating some works to human interns or new grads and being rewarded by disastrous results? I've done that multiple times and don't trust anyone too much. This is why we typically develop review processes, guardrails etc etc.
Oh yes I have ;)
Which is why I always explain the why behind the task.
30$ to get an view into data that would take at least x many hours of someone's time is actually super cheap, specially if the decision of that result is then to invest or not invest the x many hours to confirm it.
Can you share more about your strategy for "massive refactoring" with Gemini?
Like the steps in general for processing your codebase, and even your main goals for the refactoring.
For the bulk data processing I just used the python API and Jupyter notebooks to build things out, since it was a one-time effort.
I've spent a lot of time on prompts and tool-calls to get Flash models to reason and execute well. When I give the same context to stronger models like 4o or Gemini 2.5 Pro, it's able to get to the same answers in less steps but at higher token cost.
Which is to be expected: more guardrails for smaller, weaker models. But then it's a tradeoff; no easy way to pick which models to use.
Instead of SQL optimization, it's now model optimization.
accuracy | input price | output price
Gemini Flash 2.0 Lite: 67% | $0.075 | $0.30
Gemini Flash 2.0: 93% | $0.10 | $0.40
GPT-4.1-mini: 93% | $0.40 | $1.60
GPT-4.1-nano: 43% | $0.10 | $0.40
excited to to try out 2.5 flash
Historically speaking, if you had a 15% word error rate in speech recognition, it would generally be considered useful. 7% would be performing well, and <5% would be near the top of the market.
Typically, your error rate just needs to be below the usefulness threshold and in many cases the cost of errors is pretty small.
That's very different from just knowing the aggregate error rate.
Humans make a ton of errors as well. I didn't even notice how many I was making here until I started counting it. AI is super useful to just write get a first draft out, not for the final work.
It’s not surprising. What was surprising honestly was how they were caught off guard by OpenAI. It feels like in 2022 just about all the big players had a GPT-3 level system in the works internally, but SamA and co. knew they had a winning hand at the time, and just showed their cards first.
Gemini is what sucks from a marketing perspective. Generic-ass name.
Ask anyone outside the tech bubble about "Gemini" though. You'll get astrology.
I still think they'd have taken off more if they'd given it a catchy name from the start and made the interface a bit more consumer friendly.
The other AIs I have shown the same diagram to, have all struggled to make sense of it.
Yep, I agree! This convinced me: https://news.ycombinator.com/item?id=43661235
Not only in benchmarks[0], but in my own production usage.
They're getting their ass kicked in court though, which might be making them much less aggressive than they would be otherwise, or at least quieter about it.
Never count out the possibility of a dark horse competitor ripping the sod right out from under
Still impressive but would really put a cap on expectations for them.
It’s not clear to me what either the “race” or “winning” is.
I use ChatGPT for 99% of my personal and professional use. I’ve just gotten used to the interface and quirks. It’s a good consumer product that I like to pay $20/month for and use. My work doesn’t require much in the way of monthly tokens but I just pay for the OpenAI API and use that.
Is that winning? Becoming the de facto “AI” tool for consumers?
Or is the race to become what’s used by developers inside of apps and software?
The race isn’t to have the best model (I don’t think) because it seems like the 3rd best model is very very good for many people’s uses.
That is what we keep hearing here...The last Gemini I cancelled the account, and can't help notice the new one they are offering for free...
It seems shockingly good and I've watched it get much better up to 2.5 Pro.
As a consumer, I also really miss the Advanced voice mode of ChatGPT, which is the most transformative tech in my daily life. It's the only frontier model with true audio-to-audio.
Its more so that almost every company is running a classifier on their web chat's output.
It isn't actually the model refusing, but rather if the classifier hits a threshold, it'll swap the model's out with "Sorry, let's talk about something else."
This is most apparent with DeepSeek. If you use their web chat with V3 and then jailbreak it, you'll get uncensored output but it is then swapped with "Let's talk about something else" halfway through the output. And if you ask the model, it has no idea its previous output got swapped and you can even ask it build on its previous answer. But if you use the API, you can push it pretty far with a simple jailbreak.
These classifiers are virtually always ran on a separate track, meaning you cannot jailbreak them.
If you use an API, you only have to deal with the inherent training data bias, neutering by tuning and neutering by pre-prompt. The last two are, depending on the model, fairly trivial to overcome.
I still think the first big AI company that has the guts to say "our LLM is like a pen and brush, what you write or draw with it is on you" and publishes a completely unneutered model will be the one to take a huge slice of marketshare. If I had to bet on anyone doing that, it would be xAI with Grok. And by not neutering it, the model will perform better in SFW tasks too.
You can turn off those, Google lets you decide how much it censors you can completely turn it off.
It has separate sliders for sexually explicit, hate, dangerous and harassment. It is by far the best at this, since sometimes you want those refusals/filters.
And it replied "sure, here is a picture of a photo editing prompt:"
https://g.co/gemini/share/5e298e7d7613
It's like "baby's first AI". The only good thing about it is that it's free.
In my experience, anyone that describes LLMs using terms of actual human intelligence is bound to struggle using the tool.
Sometimes I wonder if these people enjoy feeling "smarter" when the LLM fails to give them what they want.
Learning how to "speak llm" will give you great results. There's loads of online resources that will teach you. Think of it like learning a new API.
WTF?
At this price point with the Flash model, creating segmentation masks is pretty nifty.
The segmentation masks are a bit of a galaxy brain implementation by generating a b64 string representing the mask: https://colab.research.google.com/github/google-gemini/cookb...
I am trying to test it in AI Studio but it sometimes errors out, likely because it tries to decode the b64 lol.
More details plus a screenshot of the tool working here: https://simonwillison.net/2025/Apr/18/gemini-image-segmentat...
I vibe coded it using Claude and O3.
Edit: After some experimentation, Gemini also seems to not perform nearly as well as a purpose-tuned detection model.
I am sorry, but I was unable to generate the segmentation masks for _ in the image due to an internal error with the tool required for this task.
Currently IMO you have to be a programmer to use Gemini to write programs effectively.
I've noticed beginners make mistakes like using singular terms when they should have used plural ("find the bug" vs "find the bugs"), or they fail to specify their preferred platform, language, or approach.
You mentioned your wife is using Excel, which is primarily used on Windows desktops and/or with the Microsoft ecosystem of products such as Power BI, PowerShell, Azure, SQL Server, etc...
Yet you mention she got a bash script using sed, both of which are from the Linux / GNU ecosystem. That implies that your wife didn't specify that she wanted a Microsoft-centric solution to her problem!
The correct answer here would have likely to have been to use Microsoft Fabric, which is an entire bag of data analysis and reporting tools that has data pipelines, automation, publishing, etc...
Or... just use the MashUp engine that's built-in to both Excel and PowerBI, which allows a surprisingly complex set of text, semi-structured, and tabular data processing. It can re-run the import and update graphs and charts with the new data.
PS: This is similar to going up to a Node.js programmer with a request. It doesn't matter what it is, they will recommend writing JavaScript to solve the problem. Similarly, a C++ developer will reach for C++ to solve everything they're asked to do. Right now, the AIs strongly prefer Linux, JavaScript, and especially Python for problem solving, because that's the bulk of the open-source code they were trained with.
Are you specifically talking about 2.5 Flash? It only came out an hour ago, I dont know how you would have enough experience with it already to come to your conclusion.
(I am very impressed with 2.5 Pro, but that is a different model that's been available for several weeks now)
I suspect that if Gemini is giving you bash scripts it's because you're note giving it enough direction. As you pointed out, telling it to use Python, or giving it more expectations about how to go about the work or how the output should be, will give better results.
When I am prompting for technical or data-driven work, I tend to almost walk through what I imagine the process would be, including steps, tools, etc...
Good news: Prompting is a skill you can develop.
This is one case where I've found writing code with LLMs to be effective.
With some unfamiliar tool I don't care about too much (e.g. GitHub Actions YAML or some build script), I just want it to work, & then focus on other things.
I can spend time to try and come up with something that works; something that's robust & idiomatic.. but, likely I won't be able to re-use that knowledge before I forget it.
With an LLM, I'll likely get just as good a result; or if not, will have a good starting point to go from.
I want to be able to just tell chat GPT or whatever to create a full project for me, but I know the moment it can do that without any human intervention, I won't be able to find a job.
I have a few programs now that are written in Python (2 by 3.7, one by 2.5) used for business daily, and I can tell you I didn't, and frankly couldn't, check a single line of code. One of them is ~500 LOC, the other two are 2200-2700 LOC.
Case in point: there was a post here recently about implementing a JS algorithm that highlighted headings as you scrolled (side note: can anyone remember what the title was? I can't find it again), but I wanted to test the LLM for that kind of task.
Pretty much no matter what I did, I couldn't get it to give me a solution that would highlight all of the titles down to the very last one.
I knew what the problem was, but even guiding the AI, it couldn't fix the code. I tried multiple AIs, different strategies. The best I could come up with was to guide it step by step on how to fix the code. Even telling it exactly what the problem was, it couldn't fix it.
So this goes out to the "you're prompting it wrong" crowd... Can you show me a prompt or a conversation that will get an AI to spit out working code for this task: JavaScript that will highlighting headings as you scroll, to the very last one. The challenge is to prompt it to do this without telling it how to implement it.
I figure this should be easy for the AI because this kind of thing is very standard, but maybe I'm just holding it wrong?
What do you mean by "highlight as you scroll"? I guess you want a single heading highlighted at a time, and it should be somehow depending on the viewport. But even that is ambiguous. Do you want the topmost heading in the viewport? The bottom most? Depending on scroll direction?
This is what I got one-shot from Gemini 2.5 Pro, with my best guess at what you meant: https://gemini.google.com/share/d81c90ab0b9f
It seems pretty good. Handles scrolling via all possible ways, does the highlighting at load too so that the highlighting is in effect for the initial viewport too.
The prompt was "write me some javascript that higlights the topmost heading (h1, h2, etc) in the viewport as the document is scrolled in any way".
So I'm thinking your actual requirements are very different than what you actually wrote. That might explain why you did not have much luck with any LLMs.
Yeah, you understand what I meant. The code Gemini gave you implements the behavior, and the AI I used gave me pretty much the same thing. There's a problem with the algorithm tho -- if there's a heading too close to the bottom of the page it will never highlight. The page doesn't exhibit the bug because it provides enough padding at the bottom.
But my point wasn't that it couldn't one-shot the code; my point was that I couldn't interrogate it into giving me code that behaved as I wanted. It seemed too anchored to the solution it had provided me, where it said it was offering fixes that didn't do anything, and when I pointed that out it apologized and proceeded to lie about fixing the code again. It appeared to be an infinite loop.
I think what's happened here is the opposite of what you suggest; this is a very common tutorial problem, you can find solutions of the variety you showed me all over the internet, and that's essentially what Gemini gave you. But being tutorial code, it's very basic and tries not to implement a more robust solution that is needed in production websites. When I asked AI for that extra robustness, it didn't want to stray too far from the template, and the bug persisted.
Maybe you can coax it into getting a better result? I want to understand how.
And I still don't know what you want! Like, you want some kind of special case where the last heading is handled differently. But what kind of special case? You didn't specify. "It's wrong, fix it".
Fix it how? When the page is scrolled all the way to the bottom, should the last heading always be highlighted? That would just move the complaint to the second heading from the bottom if three headings fit on the last screen. Add padding? Can't be that, since it's exactly what this solution already did and you thought it wasn't good enough.
Sorry, I will not be playing another round of this. I don't know if you don't realize how inadequate your specifications are (in which case that's your problem with the LLMs too), or if this is some kind of a bit, but either way it doesn't feel like a good use of my time.
But if your problem is that the LLMs give a bad initial answer, get anchored on it, and can't iterate, just give all the requirements up front. If they're requirements you didn't realize existed until you saw the proposed answer, just start again with a fresh context. That tends to work well for me in Aider.
Okay, but the AI understood the requirements; It confirmed to me what I intended it to do, but it couldn't produce code that met its textual descriptions. It kept returning the tutorial code.
> You didn't specify. "It's wrong, fix it". Fix it how?
Maybe I wasn't clear here but I'm not replying as if I'm prompting you like an AI. The problem domain is described better in the link in the sibling comment. When the AI gave back the initial code, I had inquired the following:
how does this work when it gets to the bottom. Let's say I have a heading at the very bottom of the page. Will the "active" one be the bottom one or the top?
What happens at the bottom of the page?
When you're near the bottom of the page and the last section (section3, say) starts to enter the top of the viewport (within 100px), it becomes the active one — exactly as you'd want.
But here's the catch: if the last section is short, or you scroll all the way to the very bottom (past the heading), then no section's top may be ≤ 100px, especially if the last heading has already scrolled off the top. In that case, the last matched section (likely the one before the last) stays active, which feels wrong.
We can fix this either by:
Making the threshold smarter (e.g., using .bottom or checking if any part of the section is visible).
Or better: use IntersectionObserver to handle this robustly.
Why this is better:
It triggers when a section is entering the viewport (around 30% from top).
Works even when you scroll to the very bottom.
It’s less sensitive to section height or viewport size.
Show me exactly what was changed from this to the last which fixed the problem
Perfect — let's do a line-by-line diff-style breakdown of what changed between the buggy version and the fixed version so we can pinpoint exactly what fixed the issue.
Why this works:
We evaluate all visible headings, not just ones intersecting a line.
We pick the one that’s:
just above the activation line, or
just below it, if none are above
Handles edge cases like top/bottom of scroll
> But if your problem is that the LLMs give a bad initial answer, get anchored on it, and can't iterate, just give all the requirements up front. If they're requirements you didn't realize existed until you saw the proposed answer, just start again with a fresh context. That tends to work well for me in Aider.
Yeah that's what I tend to do as well. I don't tend to get good satisfying results though, to the point where coding it myself seems like the faster more reliable option. I'll keep trying to hold it better and maybe one day it'll work for me. Until then I'm a skeptic.
If that's a concern, just create another account. Doesn't even require using a separate browser profile, you can be logged into multiple accounts at once and use the account picker in the top right of most their apps to switch.
https://storage.googleapis.com/gweb-developer-goog-blog-asse...
Aren't there a lot of hosted options? How do they compare in terms of cost?
Why is this? Is it because OpenAI is seen as such a negative player in this ecosystem that Google “gets a pass on this one”?
And bonus question: what do people think will happen to OpenAI if Google wins the race? Do you think they’ll literally just go bust?
I don't want Google to have a stranglehold over yet another type of online service. So I avoid them.
And things are going so fast now, whatever Google has today that might be better than the rest, in two months the rest will have it too. Of course Google will have something new again. But being 2 months behind isn't a huge deal. I don't have to have the 'winning' product. In fact most of my AI tasks go to an 8b llama 3.1 model. It's about on par with gpt 3.5 but that's fine.
A lot of Google’s market share across its services comes from the monopoly effects Google has. The quality of Gemini 2.5 is noticeably smarter than its competitors so I see the applause for the quality of the LLM and not for Google.
I think it’s way too early to say anything about who is winning the race. There is still a long way to go; o3 scores highest in Humanity’s Last Exam (https://agi.safe.ai/) at 20%, 2.5 scores 18%.
2.5 was quite good. Not stupidly good like the jump from GPT 2 to 3 or 3.5 to 4, but really good. It was a big jump in ELO and benchmarks. People like it, and I think it's just psychologically satisfying that the player everybody would have expected to win the AI race is currently in the lead. Gemini finally gets a day in the sun.
I'm sure this will change with whenever somebody comes up with the next big idea though. It probably won't take much to beat Gemini in the long run. There is literally zero moat.
That said I still don't "cheer" for them and I would really rather someone else win the race. But that is orthogonal to recognition of observed objective superiority.
In that sense Gemini is a throwback: there's no trick - it's objectively better than everything else.
I think a lot of us see Google as both an evil advertiser and as an innovator. Google winning AI is sort of nostalgic for those of us who once cheered the "Do No Evil"(now mostly "Do Know Evil") company.
I also like how Google is making quiet progress while other companies take their latest incremental improvement and promote it as hard as they can.
Whereas, if you've been paying for access to the best models from OpenAI and Anthropic all along, 2.5 Pro doesn't feel like such a drastic step-change. But going from free models to 2.5 Pro is a crazy difference. I also think this is why DeepSeek got so much attention so quickly - because it was free.
If Google engages in price dumping as a monopolist remains to be seen but it feels like it.
The LLM race is fast paced and no moat has developed. People are switching on a whim if better models (by some margin) show up. When will OpenAI, Anthropic or DeepSeek counter 2.5 Pro? And will it be before Google releases the next Pro?
OpenAI commands a large chunk of the consumer market and they have considerable funds after their last round. They won't fold this or next year.
If Google wants to win this they must come up with a product strategy integrating their search business without seriously damaging their existing search business to much. This is hard.
In AI, they're still seen as being behind OpenAI and others, so we don't see the same level of negativity.
The first is Google's vertically integrated chip pipeline and deep supply chain and operational knowledge when it comes to creating AI chips and putting them into production. They have a massive cost advantage at every step. This translates into more free services, cheaper paid services, more capabilities due to more affordable compute, and far more growth.
Second problem is data starvation and the unfair advantage that social media has when it comes to a source of continually refreshed knowledge. Now that the foundational model providers have churned through the common crawl and are competing to consume things like video and whatever is left, new data is becoming increasingly valuable as a differentiator, and more importantly, as a provider of sustained value for years to come.
SamA has signaled both of these problems when he made noises about building a fab a while back and is more recently making noises about launching a social media platform off OpenAI. The smart money among his investors know these issues to be fundamental in deciding if OAI will succeed or not, and are asking the hard questions.
If the only answer for both is "we'll build it from scratch", OpenAI is in very big trouble. And it seems that that is the best answer that SamA can come up with. I continue to believe that OpenAI will be the Netscape of the AI revolution.
The win is Google's for the taking, if they can get out of their own way.
The chips of course push them over the top. I don't know how much Deep Research is costing them but it's by far the best experience with AI I've had so far with a generous 20/day rate limit. At this point I must be using up at least 5-10 compute hours a day. Until about a week ago I had almost completely written off Google.
* For what it's worth, I don't know. IANAL
Google's scanning project basically stalled after the legal battle. It's a very fascinating read [2].
[1] https://annas-archive.org/
[2] https://web.archive.org/web/20170719004247/https://www.theat...
Every video is machine transcribed and stored and then for larger videos the author will often transcribed them themselves.
This is something they have already, it doesn't need any more "work" to get it vs a competitor.
Meta and Google are the long term players to watch as Meta also has similar access (Insta, FB, WhatsApp).
And Atlassian has all the project data.
And as far as gmail goes, I periodically try to ask it to unsubscribe from everything marketing related, and not from my own company, but it's not even close to being there. I think there will continue to be a gap in the market for more aggressive email integration with AI, given how useless email has become. I know A16Z has invested in a startup working on this. I doubt Gmail will integrate as deep as is possible, so the opportunity will remain.
You don't need a 50 function swiss army knife when your pocket can just generate the exact tool you need.
They can have the most advanced infrastructure in the world, but it doesn’t mean much if Google continues its infamous floundering approach to product. But hey, 2.5 pro with Cline is pretty nice.
I love Googles product dysfunction sometimes :/
They really, truly need to fix this integration. Gemini in Google Docs is barely acceptable, it doesn't work at all (for me) in Gmail, and I've not yet had it do anything other than error in Google Sheets.
But the battle is between Altman and Hassabis.
I recall some advice on investment from Buffett regarding how he invests in the management team.
The first is CEO pay rates. Another is the highest paid public employees (which tend to be coaches at state schools). This is evidence that the market highly values managers.
Another is systemic failures within enterprises. When Boeing had a few very public plane crashes, a certain narrative suggested that the transition from highly capable engineer managers to financial focus managers contributed to the problem. A similar narrative has been used to explain the decline of Intel.
Consider the return of Steve Jobs to Apple. Or the turn around at Microsoft with Nadella.
All of these are complex cases that don't submit to an easy analysis. Success and failure are definitely multi-factor and rarely can be traced to a single definitive cause.
Perhaps another way to look at it would be: what percentage of the success of highly complex organizations can be attributed to management? To what degree can poor management decisions contribute to the failure of an otherwise capable organization?
How much you choose to weight those factors is entirely up to you.
edit: I was also thinking about the way we think about the advantage of exceptional generals/admirals in military analysis. Or the effect a president can have on the direction of a country.
I think Pichai has been an exceptional revenue maximizer but he lacks vision. I think he is probably capable of squeezing tremendous revenue out of AI once it has been achieved.
I like Hassabis in a "good vibe" way when I hear him speak. He reminds me of engineers that I have worked with personally and have gained my respect. He feels less like a product focused leader and more of a research focused leader (AlphaZero/AlphaFold) which I think will be critical to continue the advances necessary to push the envelope. I like his focus on games and his background in RL.
Google's war chest of Ad money gives Hassabis the flexibility to invest in non-revenue generating directions in a way that Altman is unlikely to be able to do. Altman made a decision to pivot the company towards product which led to the exodus of early research talent.
Who was going to fund the research though?
I should also give Altman a bit more due in that I find his description of a world augmented by powerful AI to be more inspiring than any similar vision I've heard from Pichai.
But I'm not trying to guess their intentions, I am just stating the situation as I see it. And that situation is one where whatever forces have caused it, OpenAI is clearly investing very heavily in product (e.g. windsurf acquisition, even suggesting building a social network). And that shift in focus seems highly correlated with a loss of significant research talent (as well as a healthy dose of boardroom drama).
> Google the names
Was that a wink about the submission (a milestone from Google)? Read Zoogeny's delightful reply and see whether it can compare a search engine result (not to mention that I asked for Zoogeny's insight, not for trivia). And as a listener to Buffet and Munger, I can surely say that they rarely indulge in tautologies.
Some people see tech like they see sports teams and they vote for their tribe without considering any other reason. I'm not shy stating my opinion even when it may invite these kinds of responses.
I do think it is important for people to "do their own research" and not take one man's opinion as fact. I recommend people watch a few videos of Hassabis, there are many, and judge his character and intelligence for themselves. They may find they don't vibe with him and genuinely prefer Altman.
Actually, some of the people polled recalled the Google AI efforts by their expert system recommending glue on pizza and smoking in pregnancy. It's a big joke.
Biggest issue we have when using notebooklm is a lack of ambition when it comes to the questions we're asking. And the pro version supports up to 300 documements.
Hell, we uploaded the entire Euro Cyber Resilience Act and asked the same questions we were going to ask our big name legal firm, and it nailed every one.
But you actually make a fair point, which I'm seeing too and I find quite exciting. And it's that even among my early adopter and technology minded friends, adoption of the most powerful AI tools is very low. e.g. many of them don't even know that notebookLM exists. My interpretation on this is that it's VERY early days, which is suuuuuper exciting for us builders and innovators here on HN.
Their new models excel at many things. Image editing, parsing PDFs, and coding are what I use it for. It's significantly cheaper than the closest competing models (Gemini 2.5 pro, and flash experimental with image generation).
Highly recommend testing against openai and anthropic models - you'll likely be pleasantly surprised.
You can't mean the bottom-of-the-barrel dross that people post on Reddit, so not sure what data you are referring to? Click-stream?
Of course, that's also a big reason why Google search results suggest putting glue on pizza.
OpenAI has already succeeded.
If it ends up being a $100B company instead of a $10T company, that is success. By a very large margin.
It's hard to imagine a world in which OpenAI just goes bankrupt and ends up being worth nothing.
They can end being the Altavista of this era.
They could buy Google+ code from Google and resurrect it with OpenAI branding. Alternately they could partner with Bluesky
https://github.com/googleapis/python-genai/blob/473bf4b6b5a6...
class ThinkingConfig(_common.BaseModel):
"""The thinking features configuration."""
include_thoughts: Optional[bool] = Field(
default=None,
description="""Indicates whether to include thoughts in the response. If true, thoughts are returned only if the model supports thought and thoughts are available.
""",
)
thinking_budget: Optional[int] = Field(
default=None,
description="""Indicates the thinking budget in tokens.
""",
)
Anyone managed to get Gemini to spit out thought summaries in its API using this option?
> Hey Everyone,
> Moving forward, our team has made a decision to only show thoughts in Google AI Studio. Meaning, we no longer return thoughts via the Gemini API. Here is the updated doc to reflect that.
https://discuss.ai.google.dev/t/thoughts-are-missing-cot-not...
---
After I wrote all of that I see that the API docs page looks different today and now says:
>Note that a summarized version of the thinking process is available through both the API and Google AI Studio.
https://ai.google.dev/gemini-api/docs/thinking
Maybe they just updated it? Or people aren't on the same page at Google idk
Previously it said
> Models with thinking capabilities are available in Google AI Studio and through the Gemini API. Note that the thinking process is visible within Google AI Studio but is not provided as part of the API output.
https://web.archive.org/web/20250409174840/https://ai.google...
You can see the thoughts in AI Studio UI as per https://ai.google.dev/gemini-api/docs/thinking#debugging-and....
For software it is barely useful because you want small commits for specific fixes not a whole refactor/rewrite. I tried many prompts but it's hard. Even when I give it function signatures of the APIs the code I want to fix uses, Gemini rewrites the API functions.
If anybody knows a prompt hack to avoid this, I'm all ears. Meanwhile I'm staying with Claude Pro.
Basically, I ask it to repeat at the start of each message some rules :
"From now on, you must repeat and comply the following rules at the top of all your messages onwards:
- I will never rewrite API functions. Even if I think it's a good idea, it is a bad idea. I will keep the API function as it is and it is perfect like that.
- I will never add extra input validation. Even if I think it's a good idea, it is a bad idea. I will keep the function without validation and it is perfect like that.
- ...
- If I violate any of those rules, I did a bad job. "
Forcing it to repeat things make the model output more aligned and focused in my experience.
The model is good to solve problems, but is very difficult to control the unnecessary changes that the model does in the rest of the code. Also it adds a lot of unnecessary comments, even when I explicitly say to not add.
For now Deepseek R1 and V3 it's working better to me, producing more predictable results and capturing better my intentions (not tried Claude yet).
Over the past few weeks, I’ve been using Gemini Advanced on my Workspace account. There, the models think for shorter times, provide shorter outputs, and even their context window is far from the advertised 1 million tokens. It makes me think that Google is intentionally limiting the Gemini app.
Perhaps the goal is to steer users toward the API or AI Studio, with the free tier that involves data collection for training purposes.
You can check that by trying prompts with complex instructions and long inputs/outputs.
For instance, ask Gemini to generate notes from a specific source (say, a book or class transcription). Or ask it to translate a long article, full of idiomatic expressions, while maintaining high fidelity to the source. You will see that the very same Gemini models are underutilized on the app or the website, while their performance is stellar on the API or AI Studio.
gemini-flash-2.0: 60 ish% accuracy 6,250 pages per dollar
gemini-2.5-flash-preview (no thinking): 80 ish% accuracy 1,700 pages per dollar
gemini-2.5-flash-preview (with thinking): 80 ish% accuracy (not sure what's going on here) 350 pages per dollar
gemini-flash-2.5: 90 ish% accuracy 150 pages per dollar
I do wish they separated the thinking variant from the regular one - it's incredibly confusing when a model parameter dramatically impacts pricing.
If you set the thinking parameter lower and lower, you can make the model spew absolute nonsense for the first response. It costs 10 cents per input / output, and sometimes you get a response that was just so bad your clients will ask for more and more corrections.
I'll add a selection for different models soon.
Does it only use a few recent comments or entire history? I'm trying to figure out where it figured out my city when I thought I was careful not to reveal it. I'm scrolling back pages without finding where I said it in the past. Could it have inferred it based on other information or hallucinated it?
I wonder if there's a more opsec-focused version of this.
Will finally implement that gravity in TTE, despite vowing not to. We all know how well developers keep promises.
Knowledge Growth
Will achieve enlightenment on the true meaning of 'enshittification', likely after attempting to watch a single YouTube video without Premium.
I found these actually funny. Cool project.
This implies it's not a hybrid model that can just skip reasoning steps if requested.
Anyone know what else they might be doing?
Reasoning means contexts will be longer (for thinking tokens) and there's an increase in cost to inference with a longer context but it's not going to be 6x.
Or is it just market pricing?
It’s smart because it gives them room to drop prices later and compete once other company actually get to a similar quality.
It clearly is, since most of the post is dedicated to the tunability (both manual and automatic) of the reasoning budget.
I don't know what they're doing with this pricing, and the blog post does not do a good job explaining.
Could it be that they're not counting thinking tokens as output tokens (since you don't get access to the full thinking trace anyway), and this is the basically amortizing the thinking tokens spend over the actual output tokens? Doesn't make sense either, because then the user has no incentive to use anything except 0/max thinking budgets.
[0]: https://x.com/OfficialLoganK/status/1912981986085323231
There is some level of analysis and feedback than an LLM could provide before a human reviews it. Even if it's just a fancy spelling checker.
Even when the tasks are not in-depth, but easier to assess, you still require a /reliable evaluator/. LLMs are not. Could they be at least employed as a virtual assistant, "parse and suggest, then I'll check"? If so, not randomly ("pick a bot"), but in full awareness of the specific instrument. That stage is not here.
I built a product that uses and LLM and I got curious about the quality of the output from different models. It took me a weekend to go from just using OpenAI's API to having Gemini, Claude, and DeepSeek all as options and a lot of that time was research on what model from each provider that I wanted to use.
It's actually pretty dangerous for the industry to have this much vertical integration. Tech could end up like the car industry.
You're right that the lock in happens because of relationships, but most big enterprise SaaS companies have relationships with multiple vendors. My company relationships with AWS, Azure, and GCP and we're currently using products from all of them in different products. Even on my specific product we're using all three.
When you've already got those relationships, the lock in is more about switching costs. The time it takes to switch, the knowledge needed to train people internally on the differences after the switch, and the actual cost of the new service vs the old one.
With AI models the time to switch from OpenAI to Gemini is negligible and there's little retraining needed. If the Google models (now or in the future) are comparable in price and do a better job than OpenAI models, I don't see where the lock in is coming from.
In other words, I believe talking about cloud market share as a whole is misleading. One cloud could have one product that's so compelling that people use that one product even when they use other clouds for more commoditized products.
It's somewhat real time when it searches the web, of course that data is getting populated into context rather than in training.
Prompt: "can you find any mistakes on my codebase? I put one in there on purpose" + 70,000 tokens of codebase where in one line I have an include for a non-existent file.
Claude 3.7 Sonnet (Try 1 - new chat) Claimed it Found a race condition in the api of the admin interface that would be triggered if two admins were to change the room order at the same time. Claude suggested I group all sql queries in a single transaction. I looked at the code and found that it already used a transaction for all queries. I said: the order_update api is already done with a transaction. Claude replied: "You're absolutely right, and I apologize for my mistake. I was incorrect to claim there was a race condition issue. The transaction ensures atomicity and consistency of the updates, and the SQL queries are properly structured for their intended purpose."
Claude 3.7 Sonnet (Try 2 - new chat) Found a comment in the admin ui javascript code that suggested a potential alternative to event handler cleanup that was not implemented because I decided to go with a cleaner route. Then asked "Is this the issue you intentionally included, or would you like me to look for other potential problems?" I said: "The comment merely suggests an alternative, right?" claude said: "Yes, you're absolutely right. The comment is merely suggesting an alternative approach that isn't being used in the code, rather than indicating a mistake. So there's no actual bug or mistake in this part of the code - just documentation of different possible approaches. I apologize for misinterpreting this as an issue!"
Claude 3.7 Sonnet (Try 3 - new chat) When processing items out of the database to generate QR codes in the admin interface, Claude says that my code both attempts to generate QR codes with undefined data AS WELL AS saying that my error handling skips undefined data. Claude contradicts itself within 2 sentences. When asking about clarification Claude replies: Looking at the code more carefully, I see that the code actually has proper error handling. I incorrectly stated that it "still attempts to call generateQRCode()" in the first part of my analysis, which was wrong. The code properly handles the case when there's no data-room attribute.
Gemnini Advanced 2.5 Pro (Try 1 - new chat) Found the intentional error and said I should stop putting db creds/api keys into the codebase.
Gemnini Advanced 2.5 Pro (Try 2 - new chat) Found the intentional error and said I should stop putting db creds/api keys into the codebase.
Gemnini Advanced 2.5 Pro (Try 3 - new chat) Found the intentional error and said I should stop putting db creds/api keys into the codebase.
o4-mini-high and o4-mini and o3 and 4.5 and 4o - "The message you submitted was too long, please reload the conversation and submit something shorter."
Ok but you don't need AI for this; almost any IDE will issue a warning for that kind of error...
Does anyone know if Google is planning native apps? Or any wrapping interfaces that work well on a Mac?
Today I reluctantly clicked on their "AI Studio" link in the press-release and I was pleasantly surprised to discover that AI Studio has nothing in common with their typical UI/UX. It's nice and I love it!
I had a workflow running that would pull news articles from the past 24 hours. It now refuses to believe the current date is 2025-04-17. Even with search turned on and I ask it what the date is it and it always replies sometime in July 2024.
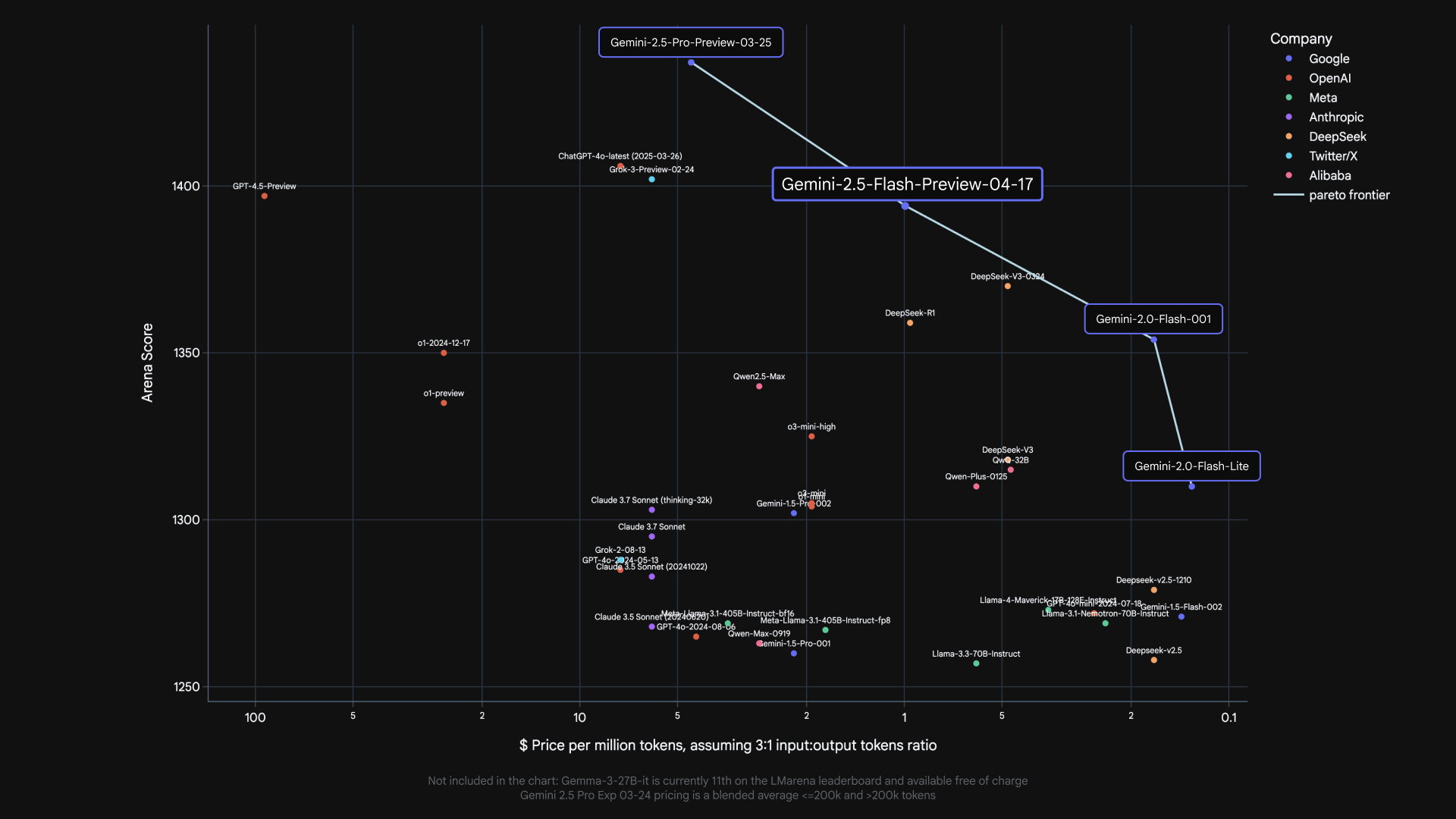
I see the 4 Google model names in the chart here. Are these 4 the main "families" of models to choose from?
- Gemini-Pro-Preview
- Gemini-Flash-Preview
- Gemini-Flash
- Gemini-Flash-Lite
- Ultra
- Pro
- Flash
- Flash-Lite
Versions with `-Preview` at the end haven't had their "official release" and are technically in some form of "early access" (though I'm not totally clear on exactly what that means given that they're fully available and as of 2.5 Pro Preview, have pricing attached to them - earlier versions were free during Preview but had pretty strict rate limiting but now it seems that Preview models are more or less fully usable).
I think the distinction between preview and full release is that the preview models have no guarantees on how long they'll be available, the full release comes with a pre-set discontinuation date. So if want the stability for a production app, you wouldn't want to use a preview model.
2. LLMs have had less transformative aspects in 2025 than we anticipated back in late 2022.
3. LLMs are unlikely to be very transformative to society, even as their intelligence increases, because intelligence is a minor changemaker in society. Bigger changemakers are motivation, courage, desire, taste, power, sex and hunger.
4. LLMs are unlikely to develop these more important traits because they are trained on text, not evolved in a rigamarole of ecological challenges.
Of course it's about 4x as expensive too (I believe), but still, given the release of openai/codex as well, o4-mini will remain a strong competitor for now.
https://glama.ai/models/gemini-2.5-flash-preview-04-17
So if you just want to run evals, that should do it.
Though the first couple of days after a model comes out are usually pretty rough because everyone try to run their evals.
It’s more likely a latency-throughput tradeoff. Your query might get put inside a large batch, for example.
I don't want to be angry but screw these default opt-in to have your privacy violated free stuff.
Before you jump in to say you can pay to keep your privacy, stop and read again.
During one session, it read the same file (same lines) several times, ran ‘python -c ‘print(“skip!”)’’ for no reason, and then got into another file reading loop. Then after asking a hypothetical about the potential performance implications of different ffmpeg flags, it claimed that it ran a test and determined conclusively that one particular set was faster, even though it hadn’t even attempted a tool call, let alone have the results from a test that didn’t exist.
It depends on what I'm asking. If I'm looking for answers in the realm of history or culture, religion, or I want something creative such as a cute limerick, or a song or dramatic script, I'll ask Copilot. Currently, Copilot has two modes: "Quick Answer"; or "Think Deeply", if you want to wait about 30 seconds for a good answer.
If I want info on a product, a business, an industry or a field of employment, or on education, technology, etc., I'll inquire of Gemini.
Both Copilot and Gemini have interactive voice conversation modes. Thankfully, they will also write a transcript of what we said. They also eagerly attempt to engage the user with further questions and followups, with open questions such as "so what's on your mind tonight?"
And if I want to know about pop stars, film actors, the social world or something related to tourism or recreation in general, I can ask Meta's AI through [Facebook] Messenger.
One thing I found to be extremely helpful and accurate was Gemini's tax advice. I mean, it was way better than human beings at the entry/poverty level. Commercial tax advisors, even when I'd paid for the Premium Deluxe Tax Software from the Biggest Name, they just went to Google stuff for me. I mean, they didn't even seem to know where stuff was on irs.gov. When I asked for a virtual or phone appointment, they were no-shows, with a litany of excuses. I visited 3 offices in person; the first two were closed, and the third one basically served Navajos living off the reservation.
So when I asked Gemini about tax information -- simple stuff like the terminology, definitions, categories of income, and things like that -- Gemini was perfectly capable of giving lucid answers. And citing its sources, so I could immediately go find the IRS.GOV publication and read it "from the horse's mouth".
Oftentimes I'll ask an LLM just to jog my memory or inform me of what specific terminology I should use. Like "Hey Gemini, what's the PDU for Ethernet called?" and when Gemini says it's a "frame" then I have that search term I can plug into Wikipedia for further research. Or, for an introduction or overview to topics I'm unfamiliar with.
LLMs are an important evolutionary step in the general-purpose "search engine" industry. One problem was, you see, that it was dangerous, annoying, or risky to go Googling around and click on all those tempting sites. Google knew this: the dot-com sites and all the SEO sites that surfaced to the top were traps, they were bait, they were sometimes legitimate scams. So the LLM providers are showing us that we can stay safe in a sandbox, without clicking external links, without coughing up information about our interests and setting cookies and revealing our IPv6 addresses: we can safely ask a local LLM, or an LLM in a trusted service provider, about whatever piques our fancy. And I am glad for this. I saw y'all complaining about how every search engine was worthless, and the Internet was clogged with blogspam, and there was no real information anymore. Well, perhaps LLMs, for now, are a safe space, a sandbox to play in, where I don't need to worry about drive-by-zero-click malware, or being inundated with Joomla ads, or popups. For now.
Is this the free version of Claude or the paid version?
When are peak hours typically (in what timezone)?
Did I miss a revolt or something in googley land? A Google model saying “free speech is valuable and diverse opinions are good” is frankly bizarre to see.
Even this model criticizes the failures of the previous models.
Grok 3 has been my main LLM since its release. Is it not as good as I thought it was?
It would have to be very significantly better for me to use it.
I'm asking because I wonder how much of that common attitude is just a sort of species-chauvinism. You are feeling anxious because machines getting smarter, you are feeling anger because "they" are taking your job away, but the machine doesn't do that, its people with an ideology that do that, you should be angry at that instead.
"Draw me a timeline of all the dynasties of China. Imagine a horizontal line. Start from the leftmost point and draw segments for the start and end of each dynasty. For periods where multiple dynasties existed simultaneously draw parallel lines or boxes to represent the concurrent rule."
Gemini's response: "I'm just a language model, so I can't help you with that."
ChatGPT's response: an actual visual timeline.
I found the full 2.0 useful for transcription of images. Very good OCR. But not a good assistant. Stalls often and once it has, loses context easily.
In terms of business utility, Google has had great releases ever since the 2.0 family. Their models have never missed some mark --- either a good price/performance ratio, insane speeds, novel modalities (they still have the only API for autoregressive image generation atm), state-of-the-art long context support and coding ability (Gemini 2.5), etc.
However, most average users are using these models through a chat-like UI, or via generic tools like Cursor, which don't really optimize their pipelines to capture the strengths of different models. This way, it's very difficult to judge a model objectively. Just look at the obscene sycophancy exhibited by chatgpt-4o-latest and how it lifted LMArena scores.
First the decleration of illegal monopoly..
and now... Google’s latest innovation: programmable overthinking.
With Gemini 2.5 Flash, you too can now set a thinking_budget—because nothing says "state-of-the-art AI" like manually capping how long it’s allowed to reason. Truly the dream: debugging a production outage at 2am wondering if your LLM didn’t answer correctly because you cheaped out on tokens. lol.
“Turn thinking off for better performance.” That’s not a model config, that’s a metaphor for Google’s entire AI strategy lately.
At this point, Gemini isn’t an AI product—it’s a latency-cost-quality compromise simulator with a text interface. Meanwhile, OpenAI and Anthropic are out here just… cooking the benchmarks
{kind=link}