> We can ask a question: how long (in nanoseconds) does it take to access a type of memory of which an average laptop has N bytes? Here's GPT's answer:
"Here's what GPT says" is not an empirical argument. If you can't do better than that (run a benchmark, cite some literature), why should I bother to read what you wrote?
The better question is: Why should you bother to read what the author didn't bother to write?
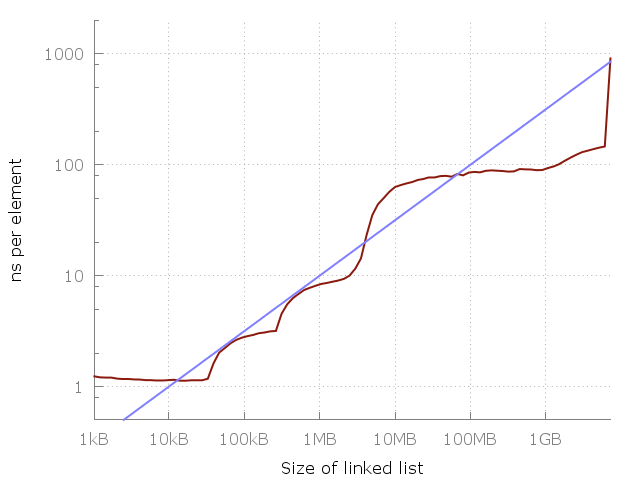
https://www.ilikebigbits.com/2014_04_21_myth_of_ram_1/3_fit.... "The blue line is O(√N)."
This has been rehashed many times before, and the best blog post on this topic is here: https://www.ilikebigbits.com/2014_04_21_myth_of_ram_1.html
https://chatgpt.com/share/68e6eeba-8284-800e-b399-338e6c4783...
https://chatgpt.com/share/68e6ef4a-bdd0-800e-877a-b3d5d4dc51...
Truly mind-boggling times where "here is the empirical proof" means "here is what chatGPT says" to some people.
I have a feeling that people who have such absolute trust in AI models have never hit regen and seen how much truth can vary.
[0] https://en.wikipedia.org/wiki/Ultimate_fate_of_the_universe?...
That doesn't apply for the Bekenstein Bound though.
Literally the first line of the wikipedia article:
> In physics, the Bekenstein bound (named after Jacob Bekenstein) is an upper limit on the thermodynamic entropy S, or Shannon entropy H, that can be contained within a given *finite* region of space which has a *finite* amount of energy—or equivalently, the maximum amount of information that is required to perfectly describe a given physical system down to the quantum level.
This has been observed since at least 2014: https://www.ilikebigbits.com/2014_04_21_myth_of_ram_1/3_fit....
Pretty much every physical metric pegs memory access as O(n^1/2).
Latency is directly bound by the speed of light. A computer the size of the earth's orbit will be bound by latency of 8 minutes. A computer the size of 2x of earth's orbit will be bound by a latency of 16 minutes, but have 4x the maximum information storage capacity.
The size of the book is directly proportional to the speed of light. Ever heard of ping? Does the universe you live in have infinite speed of light, and therefore you don't see how R contributes to latency?
And I know some of those still fit into "at least" but if one of those would make it notably worse than sqrt(n) then I stand by my claim that it's a bad speed rating.
All shared state is communicated through shared memory pool that is either accessed directly through segregated address ranges or via DMA.
The higher level the language, the less interest there is to manually manage memory. It is just something to offload to the gc/runtime/etc.
So, i think this is a no-go. The market wont accept it.
If you really want to dumb down what I’m suggesting, it’s is tantamount to blade servers with a better backplane, treating the box as a single machine instead of a cluster. If IPC replaces a lot of the RPC, you kick the Amdahl’s Law can down the road at least a couple of process cycles before we have to think of more clever things to do.
We didn’t have any of the right tooling in place fifteen years ago when this problem first started to be unavoidable, but is now within reach, if not in fact extant.
First, amdahl's law just says that the non parallel parts of a program become more of a bottleneck as the parallel parts are split up more. It's trivial and obvious, it has nothing to do with being able to scale to more cores because it has nothing to do with how much can be parallelized.
Second in your other comment, there is nothing special about "rust having the semantics" for NUMA. People have been programming NUMA machines since they existed (obviously). NUMA just means that some memory addresses are local and some are not local. If you want things to be fast you need to use the addresses that are local as much as possible.
Similar article on the same topic from 2014: https://www.ilikebigbits.com/2014_04_21_myth_of_ram_1.html
> In my binary field code, I found that an 8-bit precomputation table (in that context, 224 items taking up 128 MB) led to faster computations than a 16-bit precomputation table (232 items taking up 8 GB): while the latter fit into RAM, the former could fit into cache, and the faster access time of the former was decisive.
Interesting to see some first principles thinking to back out the “why”.
> If you can break up a task into many parts, each of which is highly local, then memory access in each part will be O(1). GPUs are already often very good at getting precisely these kinds of efficiencies. But if the task requires a lot of memory interdependencies, then you will get lots of O(N^⅓) terms. An open problem is coming up with mathematical models of computation that are simple but do a good job of capturing these nuances.
If, as stated, accessing one register requires ~0.3 ns and available registers sum up to ~2560 B, while accessing RAM requires ~80 ns and available RAM is ~32 GiB, then it means that memory access time is O(N^1/3) where N is the memory size.
Thus accessing the whole N bytes of memory of a certain kind (registers, or L1/L2/L3 cache, or RAM) takes N * O(N^1/3) = O(N^4/3).
One could argue that the title "Memory access is O(N^1/3)" refers to memory access time, but that contradicts the very article's body, which explains in detail "in 2x time you can access 8x as much memory" both in text and with a diagram.
Such statement would require that accessing the whole N bytes of memory of a certain kind requires O(N^1/3) time, while the measurements themselves produce a very different estimate: accessing the whole N bytes of memory of a certain kind requires O(N^4/3) time, not O(N^1/3)
I read "in 2x time you can access 8x as much memory" as "in 2x time you can access any byte in 8x as much memory", not "in 2x time you can access the entirety of 8x as much memory". Though I agree that the wording of that line is bad.
In normal big-O notation, accessing N bytes of memory is already O(N), and I think it's clear from context that the author is not claiming that you can access N bytes of memory in less time than O(N).
I’m confused by GP’s confusion.
No, these are different 'N's. The N in the article is the size of the memory pool over which your data is (presumably randomly) distributed. Many factors can influence this. Let's call this size M. Linear search is O(N) where N is the number of elements. It is not O(N^4/3), it is O(N * M^1/3).
There's a good argument to be made that M^(1/3) should be considered a constant, so the algorithm is indeed simply O(N). If you include M^(1/3), why are you not also including your CPU speed? The speed of light? The number of times the OS switches threads during your algorithm? Everyone knows that an O(N) algorithm run on the same data will take different speeds on different hardware. The point of Big-O is to have some reasonable understanding of how much worse it will get if you need to run this algorithm on 10x or 100x as much data, compared to some baseline that you simply have to benchmark because it relies on too many external factors (memory size being one).
> All regularly cited algorithm complexity classes are based on estimating a memory access as an O(1) operation
That's not even true: there are plenty of "memory-aware" algorithms that are designed to maximize the usage of caching. There are abstract memory models that are explicitly considered in modern algorithm design.
However, if you want to model how your algorithm scales to petabytes of data, then the model you were using breaks down, as the cost of memory access for an array that fits in RAM is much smaller than the cost of memory access for the kind of network storage that you'll need for this level of data. So, for this problem, modeling memory access as a function of N may give you a better fit for all three cases (1K items, 1G items, and 1P items).
> That's not even true: there are plenty of "memory-aware" algorithms that are designed to maximize the usage of caching.
I know they exist, but I have yet to see any kind of popular resource use them. What are the complexities of Quicksort and Mergesort in a memory aware model? How often are they mentioned compared to how often you see O(N log N) / O(N²)?
Another common scenario where this comes up and actually results in a great deal of confusion and misconceptions are hash maps, which are said to have a time complexity of O(1), but that does not mean that if you actually benchmark the performance of a hash map with respect to its size, that the graph will be flat or asymptotically approaches a constant value. Larger hash maps are slower to access than smaller hash maps because the O(1) isn't intended to be a claim about the overall performance of the hash map as a whole, but rather a claim about the average number of probe operations needed to lookup a value.
In fact, in the absolute purest form of time complexity analysis, where the operations involved are literally the transitions of a Turing machine, memory access is not assumed to be O(1) but rather O(n).
This would be true if we modeled memory access as Theta(N^{1/3}) but that's not the claim. One can imagine the data organized/prefetched in such a way that a linear access scan is O(1) per element but a random access is expected Theta(N^{1/3}). You see this same sort of pattern with well-known data structures like a (balanced) binary tree; random access is O(log(n)), but a linear scan is O(n).
is NOT what the article says.
The article says (in three ways!):
> if your memory is 8x bigger, it will take 2x longer to do a read or write to it.
> In a three-dimensional world, you can fit 8x as much memory within 2x the distance from you.
> Double the distance, eight times the memory.
the key worda there are a, which is a single access, and distance, which is a measure of time.
N is the amount of memory, and O() is the time to access an element of memory.
But when something is constrained two or three ways, it drastically reduces the incentive to prioritize tackling any one of the problems with anything but small incremental improvements.
It doesn't. Full scans are faster than accessing each memory address in an unordered way.
Let's look at a Ryzen 2600X. You can sustain 32 bytes per second from L1, 32 bytes per second from L2, and 20 bytes per cycle from L3. That's 64KB, 512KB, and 16MB caches all having almost the same bandwidth despite very different latencies.
You can also imagine an infiniband network that fills 2 racks, and another one that fills 50000 racks. The bandwidth of a single node is the same in both situations, so even though latency gets worse as you add more nodes and hops, it's going to take exactly O(n) time for a single thread to scan the entire memory.
You can find correlations between memory size and bandwidth, but they're significantly weaker and less consistent than the correlations between memory size and latency.
Technically you need to consider the time it takes to start receiving data. Which would mean your total time is O(n + ∛n). Not O(n * ∛n). But not all nodes are ∛n away. The closest nodes are O(1) latency. So if you start your scan on the close nodes, you will keep your data link saturated from the start, and your total time will be O(n). (And O(n + ∛n) simplifies to O(n) anyway.)
If you require the full scan to be done in a specific order however, indeed, in the worse case, you have to go from one end of the cube to the other between each reads, which incurs a O(n^{1/3}) multiplicative cost. Note that this does not constitute a theoretical lower-bound: it might be possible to detect those jumps and use the time spent in a corner to store a few values that will become useful later. This does look like a fun computational problem, I don't know it's exact worst-case complexity.
That way O is the function and it's a function of N.
The current way it's notated, O is the effectively the inverse function.
Saying that a function f(n) is in the class O(g(n)) means that there exists an M and a C such that f(n) < C * g(n) for any n < M. That is, it means that, past some point, f(n) is always lower than C * g(n), for some constant C. For example, we can say the function f(n) = 2n+ 1 is in the class O(n), because 2n + 1 < 7n for any n > 1. Technically, we can also say that our f(n) is in the complexity class O(2^n), because 2n + 1 < 2^n for any n >= 3, but people don't normally do this. Technically, what we typically care about is not O(f(n)), it's more of a "least upper bound", which is closer to big_theta(n).
Secondly, it's a common misconception that O(f(n)) refers to worst case complexity. O(f(n)) is an upper bound on the asymptotic growth of f(n). This upper bound can be used to measure best case complexity, worst case complexity, average case complexity, or many other circumstances. An upper bound does not mean worst case.
For example I often perform code reviews where I will point out that a certain operation is implemented with the best case scenario having O(log(N)), but that an alternative implementation has a best case scenario of O(1) and consequently I will request an update.
I expect my engineers to know what this means without mixing up O(N) with worst-case scenarios, in particular I do not expect an improvement to the algorithm in the worst case scenario but that there exists a fast/happy path scenario that can avoid doing a lot of work.
Consequently the opposite can also happen, an operation might be implemented where the worst case scenario is o(N), note the use of little-o rather than big-o, and I will request a lower bound on the worst case scenario.
That being said, I do still like the fundamental idea of figuring out a rough but usable O-estimate for random memory access speeds in a program. It never hurts to have more quick estimation tools in your toolbox.
Theoretically, it still doesn't hold up, at least not for the foreseeable future. PCBs and integrated circuits are basically two-dimensional. Access times are limited by things like trace lengths (at the board level) and parasitics (at the IC level), none of which are defined by volume.
Source: "What every Programmer should know about memory" https://people.freebsd.org/~lstewart/articles/cpumemory.pdf
Why didn’t computers have 128 terabytes of memory ten years ago? Because the access time would have been shit. You’re watching generation after generation of memory architectures compromise between access time and max capacity and drawing the wrong conclusions. If memory size were free we wouldn’t have to wait five years to get twice as much of it.
A modern CPU can perform hundreds or even thousands of computations while waiting for a single word to be read from main memory - and you get another order of magnitude slowdown if we're going to access data from an SSD. This used to be much closer to 1:1 with old machines, say in the Pentium 1-3 era or so.
And regardless of any speedup, the point remains as true today as it has always been: the more memory you want to access, the slower accessing it will be. Retrieving a word from a pool of 50PB will be much slower than retrieving a word from a pool of 1MB, for various fundamental reasons (even address resolution has an impact, even if we want to ignore physics).
Memory bandwidth has improved, but it hasn't kept up with memory size or with CPU speeds. When I was a kid you could get a speedup by using lookup tables for trig functions - you'd never do that today, it's faster to recalculate.
2D vs 3D is legit, I have seen this law written down as O(sqrt N) for that reason. However, there's a lot of layer stacking going on on memory chips these days (especially flash memory or HBM for GPUs) so it's partially 3D.
> PCBs and integrated circuits are basically two-dimensional.
Yes, what pushes the complexity into Ω(n^1/2), that fits the original claim.
> Access times are limited by things like trace lengths
Again, Ω(n^1/2)
> and parasitics
And those are Ω(n)
So, as you found, on practice it's much worse, but the limit on the article is also there.
As far as the theoretical argument... idk could be true but i suspect this is too simple a model to give useful results.
Bucketed response times still follow a curve as the X axis goes to infinity.
It’s really the same for addition and multiplication. If the add fits into a register it seems like it’s O(1j but if you’re dealing with Mersenne prime candidates the lie becomes obvious.
That we aren’t acknowledging any of this with cloud computing is quite frustrating. You can’t fit the problem on one core? Next bucket. Can’t fit it in one server? Next bucket. One rack? One data center? So on and so forth.
Order of complexity tells us which problems we should refuse to take on at all. You always have to remember that and not fool yourself into thinking the subset that is possible is the entire problem space. It’s just the productive slice of it.
Sometimes everything else is O(0)
If it turns out the universe is holographic, then you have the same bound. This might just be enforment of the holographic principle...
My understanding is that different levels of cache and memory are implemented pretty differently to optimize for density/speed. As in, this scaling is not the result of some natural geometric law, but rather because it was designed this way by the designers for those chips to serve the expected workloads. Some chips, like the mainframe CPUs by IBM have huge caches, which might not follow the same scaling.
I'm no performance expert, but this struck me as odd.
The actual formula used (at the bottom of the ChatGPT screenshot) includes corrections for some of these factors, without them it'd have the right growth rate but yield nonsense.
Like you said, thermal and cost constraints dwarf the geometrical one. But I guess my point is that they make it a non-issue and therefore isn't a sound theoretical explanation as to why memory access is O(N^[1/3]).
The difference is we spread them out into differently optimized volumes instead of build a homogenous cube, which is (most likely IMO) where most of the constant factors come from.
I think this is the part the article glossed over to just get to showing the empirical results, but I also don't feel it's an inherently unreasonable set of assumptions. At the very least, matches what the theoretical limit would be in the far future even if it were to only happen to coincidentally match current systems for other reasons.
I get the impression that backside power was the last big Dennard-adjacent win, and that’s more about relocating some of the heat to a spot closer to the chip surface, which gives thermal conductivity a boost since the heat has to move a shorter distance to get out. I think that leaves gallium, optical communication to create less heat in the bulk of the chip, and maybe new/cheaoer silicon on insulator improvements for less parasitic loss? What other things are still in the bag of tricks? Because smaller gates isn’t.
I don't know; every time Intel/AMD increase cache size it also takes more cycles. That sounds like a speed of light limit.
That this latency is of the same order as if you were putting bits in a cube is more coincidental than anything.
Edit to add: And on further reflection, this won’t save you. Because the heat production in the hypercube is a function of internal volume, but the heat dissipation is a function of the interface with 3D space, so each hypercube is limited in size, and must then be separated in time or space to allow that heat to be transferred away, which takes up more than O(n^(1/3)) distance and distance means speed of light delays.
Star interconnects are limited to the surface area of each device, which is the cube root of the volume. Because you have to have space to plug the wires in.
“You’ve got it all figured out” is deflecting basic physics facts. What is your clever solution to data center physics?
Acknowledging that memory access is not instantaneous immediately throws you into the realm of distributed systems though and something much closer to an actor model of computation. It's a pretty meaningful theoretical gap, more so than people realize.
Many of the products we use, and for probably the last fifty years really, live in the space between theory and practice. We need to collect all of this and teach it. Computer has grown 6, maybe more orders of magnitude since Knuth pioneered these techniques. In any other domain of computer science the solutions often change when the order of magnitude of the problem changes, and after several it’s inescapable.
Having to go back to inlining calculations is going to hurt my soul in tiny ways.
In Knuth's description[1] of Big-O notation (and related variants), from 1976, he starts out by saying:
Most of us have gotten accustomed to the idea of using the notation O(f(n)) to stand for any function whose magnitude is upper-bounded by a constant times f(n) , for all large n .
This is actually pretty common in CS. For example, people will often say that the typical case complexity of Quicksort is O(N log N), even though the worse case complexity is O(N^2). I doubt you'll find anyone who can tell you off the top of their head what is the actual complexity function of quicksort, and that will depend anyway on details of how the exact algorithm is implemented, even in pseudocode (will it do N reads, or 2N reads?).
Let's take a simple example: linear search. The worse case complexity is that we need to read every element from the array, and then compare it to the desired value, and we never find the desired value. So, in the worse case, the runtime is 2N (N reads + N comparisons) - f_worse(n) = 2n. In the best case, we read the first item in the array, we compare it to the pivot, and it is equal - so we need 2 operations - f_best(n) = 2. Now, we can say that O(f_worse(n)) = O(2n) = O(n). And we can also say that O(f_best(n)) = O(2) = O(1). So the best case complexity for linear search is O(1), and the worse case complexity is O(n). We never want to remember details like this to say things like "the best case complexity of linear search is 2".
The real RAM model “in theory” tells me that memory access is O(1). Of course real RAM is a spherical cow but like we could use a bit more rigor
> In computational complexity theory, and more specifically in the analysis of algorithms with integer data, the transdichotomous model is a variation of the random-access machine in which the machine word size is assumed to match the problem size.
I'm seeing some commenters happily adding 1/3 to the exponent of other algorithms. This insight does not make an O(N^2) algorithm O(N^7/3) or O(N^8/3) or anything else; those are different Ns. It might be O(N^2 + (N*M)^1/3) or O((N * M^(1/3))^2) or almost any other combination, depending on the details of the algorithm.
Early algorithm design was happy to treat "speed of memory access" as one of these constants that you don't worry about until you have a speed benchmark. If my algorithm takes 1 second on 1000 data points, I don't care if that's because of memory access speed, CPU speed, or the speed of light -- unless I have some control over those variables. The whole reason we like O(N) algorithms more than O(N^2) ones is because we can (usually) push them farther without having to buy better hardware.
More modern algorithm design does take memory access into account, often by trying to maximize usage of caches. The abstract model is a series of progressively larger and slower caches, and there are ways of designing algorithms that have provable bounds on their usage of these various caches. It might be useful for these algorithms to assume that the speed of a cache access is O(M^1/3), where M is the size of memory, but that actually lowers their generality: the same idea holds between L2 -> L3 cache as L3 -> RAM and even RAM -> Disk, and certainly RAM -> Disk does not follow the O(M^1/3) law. See https://en.wikipedia.org/wiki/Cache-oblivious_algorithm
So basically this matters for people who want some idea of how much faster (or slower) algorithms might run if they change the amount of memory available to the application, but even that depends so heavily on details that it's not likely to be "8x memory = 2x slower". I'd argue it's perfectly fine to keep M^(1/3) as one of your constants that you ignore in algorithm design, even as you develop algorithms that are more cache- and memory-access-aware. This may justify why cache-aware algorithms are important, but it probably doesn't change their design or analysis at all. It seems mainly just a useful insight for people responsible for provisioning resources who think more hardware is always better.
Accessing any given one byte in the address space is amortized to O(1)
See eg "The Myth of RAM": https://www.ilikebigbits.com/2014_04_21_myth_of_ram_1.html
8^(1/3) is 2
So according to OP (and you by agreement), upgrading my machine from 4GB of RAM to 32GB should double my RAM access time. Obviously, and demonstrably, nothing of the sort occurs!
"The von Neumann bottleneck is impeding AI computing?" (2025) https://news.ycombinator.com/item?id=45398473 :
> How does Cerebras WSE-3 with 44GB of 'L2' on-chip SRAM compare to Google's TPUs, Tesla's TPUs, NorthPole, Groq LPU, Tenstorrent's, and AMD's NPU designs?
From https://news.ycombinator.com/item?id=42875728 :
> WSE-3: 21 PB/S
From https://hackernoon.com/nvidias-mega-machine-crushes-all-of-2... :
> At Computex 2025, Nvidia’s Jensen Huang dropped a bombshell: the NVLink Spine, a compute beast pumping 130 terabytes per second, eclipsing the internet’s 2024 peak of 112.5 TB/s.
"A Comparison of the Cerebras Wafer-Scale Integration Technology with Nvidia GPU-based Systems for Artificial Intelligence" (2025-03) https://arxiv.org/abs/2503.11698v1
When we say something is O(1), we're saying that there is a constant upper bound on time to compute the algorithm. It is constant time if it takes no longer to to perform the algorithm when `n` becomes large. O(1) simply means the worst case time to compute is independent of `n`. If the algorithm is accessing storages of varying latencies, then the baseline is the slowest medium.
For small `n` (ie, what might fit into cache), Big-O notation is not really that useful. When `n` is tiny a O(n) algorithm can outperform a O(1) algorithm. The notation doesn't tell us anything about how efficient a particular implementation is. It is mainly useful when we're talking about `n` which can grow to large sizes, where whatever micro-optimizations we, or the machine might perform are dominated by `n`.
This is well known for doing large number arithmetic. For example, we typically consider that a+a is an operation that takes O(1) time to execute. This is because we know we are limiting the analysis to small numbers, even if we have a lot of them. But if the numbers can be arbitrarily large, then a+a doesn't take O(1) time, it takes O(log a) time. So, an algorithm that needs to perform O(N) additions doesn't take O(N) time, it takes O(N log K) time. And if we are doing something like adding the first N numbers, the complexity is actually O(N log N), not O(N).
The same thing happens to memory: if we assume that the problem will fit into very fast memory even for the largest sizes, we can indeed approximate memory access as O(1). But if we admit that the more memory we need to store the components of the problem, the slower memory access will get, then we need to model the cost of accessing memory as a function of program size - and the author is proposing O(N^1/3) as that cost. This means that our algorithm for adding the first N numbers actually requires O(N^4/3) time for reading N numbers from memory and then O(N log N) additions, which gives it a total complexity of O(N^4/3 + N log N) = O(N^4/3).
Now, this type of analysis is not useful if we think all our numbers will fit into a single computer's memory, probably. But if we are trying to, say, figure out how our algorithm will scale from gigabytes of data to hundreds of petabytes of data, we need to model the rising cost of memory access as our data set gets bigger too. At some point as N grows to infinity, even just computing the address of the next byte becomes a complex operation that can take longer than the whole time it took to add the first 100GB of numbers.
In English: There is some worst-case time taken to compute the algorithm that adding any further `n` will not take any longer.
For example, say we want to read the last number from an array. We get given the array index as an input, and we need to perform one memory read. You'd typically say that such an algorithm has a complexity of O(1).
However, if you actually write this algorithm and benchmark it for N=1, N=1MB, N=1GB, N=1TB, N=1PB and so on, you'll find that each of these is larger than the next. You'll also find that this number never stops growing. Accessing the last item in an array that is as large as a planet will take longer than accessing the last item in an array that is as large as a continent. So the actual complexity class is greater than O(1). Maybe O(n^1/3) is a good, maybe O(n^1/2) is better, maybe O(log n) would be best - whatever it is, it's not a constant.
{kind=link}