Every quarter he would have an all company meeting, and people would get to post questions on a site, and they would pick the top voted questions to answer.
I posted mine: "We're well into the year, and I still don't know what an AI PC is and why anyone would want it instead of a CPU+GPU combo. What is an AI PC and why should I want it?" I then pointed out that if a tech guy like me, along with all the other Intel employees I spoke to, cannot answer the basic questions, why would anyone out there want one?
It was one of the top voted questions and got asked. He answered factually, but it still wasn't clear why anyone would want one.
A lot of them are incorporating AI in their workflow, so making local AI better would be a plus. Unfortunately I don't see this happening unless GPUs come with more VRAM (and AI companies don't want that, and are willing to spend top dollar to hoard RAM)
But nothing that translated to real world end user experience (other than things like live transcription). I recall I specifically asked "Will Stable Diffusion be much faster than a CPU?" in my question.
He did say that the vendors and Microsoft were trying to come up with "killer applications". In other words, "We'll build it, and others will figure out great ways to use it." On the one hand, this makes sense - end user applications are far from Intel's expertise, and it makes sense to delegate to others. But I got the sense Microsoft + OEMs were not good at this either.
WTF is an NPU ? What kind of instructions does it support ? Can it add 3 and 5 ? Can it compute matrices ?
A retarded GPU that does matrix multiplication.
https://en.wikipedia.org/wiki/Neural_processing_unit
In theory, its your math coprocessor for your 386.
Do you feel your question was the reason this is no longer the case? (Honestly curious, not /s.)
And LLM inference is heavily memory bandwidth bound (reading input tokens isn't though - so it _could_ be useful for this in theory, but usually on device prompts are very short).
So if you are memory bandwidth bound anyway and the NPU doesn't provide any speedup on that front, it's going to be no faster. But has loads of other gotchas so no real "SDK" format for them.
Note the idea isn't bad per se, it has real efficiencies when you do start getting compute bound (eg doing multiple parallel batches of inference at once), this is basically what TPUs do (but with far higher memory bandwidth).
> usually on device prompts are very short
Sure, but that might change with better NPU support, making time-to-first-token quicker with larger prompts.
Obviously in the future this might change. But as we stand now dedicated silicon for _just_ LLM prefill doesn't make a lot of sense imo.
NPUs are racing stripes, nothing more. No killer features or utility, they probably just had stock and a good deal they could market and tap into the AI wave with.
OK, but where can I find demo applications of these that will blow my mind (and make me want to buy a PC with an NPU)?
This is normal, standard, expected behavior, not blow your midn stuff. Everyone is used to having it. But where do you think the computation is happening? There's a reason that a few years back Apple pushed to deprecate older systems that didn't have the NPU.
Are they more performant? Hell no. But if you're going to do the calculation, and if you don't care about latency or throughput (e.g. batched processing of vector encodings), why not use the NPU?
Especially on mobile/edge consumer devices -- laptops or phones.
I don’t know how good these neural engines are, but transistors are dead-cheap nowadays. That makes adding specialized hardware a valuable option, even if it doesn’t speed up things but ‘only’ decreases latency or power usage.
"You multiply matrices of INT8s."
"OH... MY... GOD"
NPUs really just accelerate low-precision matmuls. A lot of them are based on systolic arrays, which are like a configurable pipeline through which data is "pumped" rather than a general purpose CPU or GPU with random memory access. So they're a bit like the "synergistic" processors in the Cell, in the respect that they accelerate some operations really quickly, provided you feed them the right way with the CPU and even then they don't have the oomph that a good GPU will get you.
To me, an NPU and how it's described just looks like a pretty shitty and useless FPGA that any alternative FPGA from Xilinx could easily replace.
Haven't used SSE instructions for anything other than fiddling around with it yet, so I don't know if I'm wrong in this assumption. I understand the lock state argument about cores due to always max 2 cores being able to access the same cache/memory... but doesn't this have to be identical for FPUs if we compare this with SIMD + AVX?
(it’s still amazing to me that I can download a 15GB blob of bytes and then that blob of bytes can be made to answer questions and write prose)
But the NPU, the thing actually marketed for doing local AI just sits there doing nothing.
(The EC is a little microcontroller programmed by the OEM that does things like handling weird button presses.)
There are also reports of people having decent results using keyd to remap the synthetic keystrokes from the copilot button.
(The sheer number of times Microsoft has created totally different specs for how OEMs should implement different weird buttons is absurd.)
It turned out to be an incorrect gamble but maybe it wasn’t a crazy one to make at the time.
There is also a chicken and egg problem of software being dependent on hardware, and hardware only being useful if there is software to take advantage of its features.
That said I haven’t used Windows in 10 years so I don’t have a horse in this race.
In the 90s, as a developer you couldn't depend on that a user's computer had a 3D accelerator (or 3D graphics) card. So 3D video games used multiple renderers (software rendering, hardware-accelerated rendering (sometimes with different backends like Glide, OpenGL, Direct3D)).
Couldn't you simply write some "killer application" for local AI that everybody "wants", but which might be slow (even using a highly optimized CPU or GPU backend) if you don't have an NPU. Since it is a "killer application", very many people will still want to run it, even if the experience is slow.
Then as a hardware vendor, you can make the big "show-off" how much better the experience is with an NPU (AI PC) - and people will immediately want one.
Exactly the same story as for 3D accelerators and 3D graphics card where Quake and Quake II were such killer applications.
The NPU will just become a mundane internal component that isn't marketed.
What we want as users: To have advanced functionality without having to pay for a model or API and having to auth it with every app we're using. We also want to keep data on our devices.
What trainers of small models want: A way for users to get their models on their devices, and potentially pay for advanced, specialized and highly performant on-device models, instead of APIs.
Regardless if it does zilch or some minor good for you in the battery respect, the point was more NPUs don't deliver on the above reasons everyone was supposed to want AI for. Most likely, IMO, because they are far too weak to do so and making them powerful takes too much power+cost.
If you're using a recent phone with a camera, it's likely using ML models that may or may not be using AI accelerators/NPUs on the device itself. The small models are there, though.
Same thing with translation, subtitles, etc. All small local models doing specialized tasks well.
You could have 4-10 additional CPU cores, or 30-100MB more L3 cache. I would definitely rather have more cores or cache, than a slightly more efficient background blurring engine.
What examples do you have of making the NPU in this processor useful please?
On the RAM bandwidth side it depends if you want to look at it as "glass is half full" or "glass is half empty". For "glass is half full" the GPU has access to a ton of RAM at ~2x-4x the bandwidth of normal system memory an iGPU would have and so you can load really big models. For "glass is half empty" that GPU memory bandwidth is still nearly 2x less than a even a 5060 dGPU (which doesn't have to share any of that bandwidth with the rest of the system), but you won't fit as large of a model on a dGPU and it won't be as power efficient.
Speaking of power efficiency - it is decently power efficient... but I wouldn't run AI on battery on mine unless I was plugged in anyways as it still eats through the battery pretty quick when doing so. Great general workstation laptop for the size and wattage though.
They (Dell) promised a lot in their marketing, but we're like several years into the whole Copilot PC thing and you still can barely, if at all, use sane stacks with laptop NPUs.
Then where is a demo application from Microsoft of a model that I can run locally where my user experience is so much better (faster?) if my computer has an NPU?
I hope not. Sure they’re helpful, but I’d rather they sit idle behind the scenes, and then only get used when a specific need arises rather than something like a Holodeck audio interface
The Cell SPE was extremely fast but had a weird memory architecture and a small amount of local memory, just like the NPU, which makes it more difficult for application programmers to work with.
To be fair, SIMD made a massive difference for early multimedia PCs for things like music playback, gaming, and composited UIs.
As far as I am aware, AMD implemented has implemented many parts of AVX-512 in their consumer CPUs since Zen 4:
https://en.wikipedia.org/w/index.php?title=AVX-512&oldid=133...
On the other hand, Intel still does not support AVX-512 in Raptor Lake, Meteor Lake and Arrow Lake:
> https://en.wikipedia.org/wiki/Raptor_Lake
I wish every consumer product leader would figure this out.
For example, if you close a youtube browser tab with a comment half written it will pop up an `alert("You will lose your comment if you close this window")`. It does this if the comment is a 2 page essay or "asdfasdf". Ideally the alert would only happen if the comment seemed important but it would readily discard short or nonsensical input. That is really difficult to do in traditional software but is something an LLM could do with low effort. The end result is I only have to deal with that annoying popup when I really am glad it is there.
That is a trivial example but you can imagine how a locally run LLM that was just part of the SDK/API developers could leverage would lead to better UI/UX. For now everyone is making the LLM the product, but once we start building products with an LLM as a background tool it will be great.
It is actually a really weird time, my whole career we wanted to obfuscate implementation and present a clean UI to end users, we want them peaking behind the curtain as little as possible. Now everything is like "This is built with AI! This uses AI!".
I don't think that's a great example, because you can evaluate the length of the content of a text box with a one-line "if" statement. You could even expand it to check for how long you've been writing, and cache the contents of the box with a couple more lines of code.
An LLM, by contrast, requires a significant amount of disk space and processing power for this task, and it would be unpredictable and difficult to debug, even if we could define a threshold for "important"!
Sort of like how most of the time when people proposed a non-cryptocurrency use for "blockchain", they had either re-invented Git or re-invented the database. The similarity to how people treat "AI" is uncanny.
Likewise when smartphones were new, everyone and their mother was certain that random niche thing that made no sense as an app would be a perfect app and that if they could just get someone to make the app they’d be rich. (And of course ideally, the idea haver of the misguided idea would get the lions share of the riches, and the programmer would get a slice of pizza and perhaps a percentage or two of ownership if the idea haver was extra generous.)
I read this post yesterday and this specific example kept coming back to me because something about it just didn't sit right. And I finally figured it out: Glancing at the alert box (or the browser-provided "do you want to navigate away from this page" modal) and considering the text that I had entered takes... less than 5 seconds.
Sure, 5 seconds here and there adds up over the course of a day, but I really feel like this example is grasping at straws.
So much of it nowadays is like the blockchain craze, trying to use it as a solution for every problem until it sticks.
> Boss kept suggesting shoving AI into features, and I kept pointing out we could make the features better with less effort using simple heuristics in a few lines of code
there are definitely useful applications for end user features, but a lot of this is ordered from on-high top-down and product managers need to appease them...
I'd put this in "save 5 seconds daily" to be generous. Remember that this is time saved over 5 years.
Granted, it seems the even better UX is to save what the user inputs and let them recover if they lost something important. That would also help for other things, like crashes, which have also burned me in the past. But tradeoffs, as always.
I tell the computer what to do, not the other way around.
Wouldn't you just hit undo? Yeah, it's a bit obnoxious that Chrome for example uses cmd-shift-T to undo in this case instead of the application-wide undo stack, but I feel like the focus for improving software resilience to user error should continue to be on increasing the power of the undo stack (like it's been for more than 30 years so far), not trying to optimize what gets put in the undo stack in the first place.
The problem is that by agreeing to close the tab, you're agreeing to discard the comment. There's currently no way to bring it back. There's no way to undo.
AI can't fix that. There is Microsoft's "snapshot" thing but it's really just a waste of storage space.
Because:
1. Undo is usually treated as an application-level concern, meaning that once the application has exited there is no specific undo, as it is normally though of, function available. The 'desktop environment' integration necessary for this isn't commonly found.
2. Even if the application is still running, it only helps if the browser has implemented it. You mention Chrome has it, which is good, but Chrome is pretty lousy about just about everything else, so... Pick your poison, I guess.
3. This was already mentioned as the better user experience anyway, albeit left open-ended for designers, so it is not exactly clear what you are trying to add. Did you randomly stop reading in the middle?
I'm not sure we need even local AI's reading everything we do for what amounts to a skill issue.
That doesn't sound ideal at all. And in fact highlights what's wrong with AI product development nowadays.
AI as a tool is wildly popular. Almost everyone in the world uses ChatGPT or knows someone who does. Here's the thing about tools - you use them in a predictable way and they give you a predictable result. I ask a question, I get an answer. The thing doesn't randomly interject when I'm doing other things and I asked it nothing. I swing a hammer, it drives a nail. The hammer doesn't decide that the thing it's swinging at is vaguely thumb-shaped and self-destruct.
Too many product managers nowadays want AI to not just be a tool, they want it to be magic. But magic is distracting, and unpredictable, and frequently gets things wrong because it doesn't understand the human's intent. That's why people mostly find AI integrations confusing and aggravating, despite the popularity of AI-as-a-tool.
Sawstop literally patented this and made millions and seems to have genuinely improved the world.
I personally am a big fan of tools that make it hard to mangle my body parts.
If you want to tell me that llms are inherently non-deterministic, then sure, but from the point of view of a user, a saw stop activating because the wood is wet is really not expected either.
(Though, of course, there certainly are people who dislike sawstop for that sort of reason, as well.)
That is more what I am advocating for, subtle background UX improvements based on an LLMs ability to interpret a users intent. We had limited abilities to look at an applications state and try to determine a users intent, but it is easier to do that with an LLM. Yeah like you point out some users don't want you to try and predict their intent, but if you can do it accurately a high percentage of the time it is "magic".
I'd wager it's more likely to be the opposite.
Older UIs were built on solid research. They had a ton of subtle UX behaviors that users didn't notice were there, but helped in minor ways. Modern UIs have a tendency to throw out previous learning and to be fashion-first. I've seen this talked about on HN a fair bit lately.
Using an old-fashioned interface, with 3D buttons to make interactive elements clear, and with instant feedback, can be a nicer experience than having to work with the lack of clarity, and relative laggyness, of some of today's interfaces.
Yes. For example, Chrome literally just broke middle-click paste in this box when I was responding. It sets the primary selection to copy, but fails to use it when pasting.
Middle click to open in new tab is also reliably flaky.
I really miss the UI consistency of the 90s and early 2000s.
Rose tinted glasses perhaps, but I remember it as a very straightforward and consistent UI that provided great feedback, was snappy and did everything I needed. Up to and including little hints for power users like underlining shortcut letters for the & key.
Microsoft seems not to believe that users want to use search primarily as an application launcher, which is strange because Mac, Linux, and mobile have all converged on it.
And even that's only because browsers ended up in a weird "windows but tabs but actually tabs are windows" state.
So yeah, I'd miss the UX of dragging tabs into their own separate windows.
But even that is something that still feels janky in most apps ( windows terminal somehow makes this feel bad, even VS code took a long time to make it feel okay ), and I wouldn't really miss it that much if there were no tabs at all and every tab was forced into a separate window at all times with it's own task bar entry.
The real stuff not on Win95 that everyone would miss is scalable interfaces/high DPI (not necessary as in HiDPI, just above 640x480). And this one does require A LOT of resources and is still wobbly.
You could have multiple windows, and you could have MDI windows, but you couldn't have shared task bar icons that expand on hover to let you choose which one to go to.
If you mean that someone could write a replacement shell that did that, then maybe, but at that point it's no longer really windows 95.
One of the episodes had them using Windows 98. As I recall, the reaction was more or less "this is pretty ok, actually". A few WTFs about dialup modems and such, but I don't recall complaints about the UI.
And nobody relied on them when they were distracting and unpredictable. People only rely on them now because they are not.
LLMs won't ever be predictable. They are designed not to be. A predictable AI is something different from a LLM.
Like what? All those popups screaming that my PC is unprotected because I turned off windows firewall?
The hard part is the AI needs to be correct when it doesn't something unexpected. I don't know if this is a solvable problem, but it is what I want.
I want reproducibility not magic.
If your "AI" light switch doesn't turn on the lights, you have to rephrase the prompt.
The funny thing is that this exact example could also be used by AI skeptics. It's forcing an LLM into a product with questionable utility, causing it to cost more to develop, be more resource intensive to run, and behave in a manner that isn't consistent or reliable. Meanwhile, if there was an incentive to tweak that alert based off likelihood of its usefulness, there could have always just been a check on the length of the text. Suggesting this should be done with an LLM as your specific example is evidence that LLMs are solutions looking for problems.
If the computer can tell the difference and be less annoying, it seems useful to me?
We should keep in mind that we're trying to optimize for user's time. "So, she cheated on me" takes less than a second to type. It would probably take the user longer to respond to whatever pop up warning you give than just retyping that text again. So what actual value do you think the LLM is contributing here that justifies the added complexity and overhead?
Plus that benefit needs to overcome the other undesired behavior that an LLM would introduce such as it will now present an unnecessary popup if people enter a little real data and intentionally navigate away from the page (and it should be noted, users will almost certainly be much more likely to intentionally navigate away than accidentally navigate away). LLMs also aren't deterministic. If 90% of the time you navigate away from the page with text entered, the LLM warns you, then 10% of the time it doesn't, those 10% times are going to be a lot more frustrating than if the length check just warned you every single time. And from a user satisfaction perspective, it seems like a mistake to swap frustration caused by user mistakes (accidentally navigating away) with frustration caused by your design decisions (inconsistent behavior). Even if all those numbers end up falling exactly the right way to slightly make the users less frustrated overall, you're still trading users who were previously frustrated at themselves for users being frustrated at you. That seems like a bad business decision.
Like I said, this all just seems like a solution in search of a problem.
If I want to close the tab of unsubmitted comment text, I will. I most certainly don’t need a model going “uhmmm akshually, I think you might want that later!”
Close enough for the issue to me and can't be more expensive than asking an LLM?
Literally "T-shirt with Bluetooth", that's what 99.98% of "AI" stickers today advertise.
No, ideally I would be able to predict and understand how my UI behaves, and train muscle memory.
If closing a tab would mean losing valuable data, the ideal UI would allow me to undo it, not try to guess if I cared.
There isn't even an "I've watched this" or "don't suggest this video anymore" option. You can only say "I'm not interested" which I don't want to do because it will seems like it will downrank the entire channel.
Even if that is the case, I rarely watch the same video, so the recommendation engine should be able to pick that up.
But that's the real problem. You can't just average everyone and apply that result to anyone. The "average of everyone" fits exactly NO ONE.
The US Navy figured this out long ago in a famous anecdote in fact. They wanted to fit a cockpit to the "average" pilot, took a shitload of measurements of a lot of airmen, and it ended up nobody fit.
The actual solution was customization and accommodations.
Convince them to sink their fortunes in, and then we just make sure it pops.
When "asdfasdf" is actually a package name, and it's in reply to a request for an NPM package, and the question is formulated in a way that makes it hard for LLMs to make that connection, you will get a false positive.
I imagine this will happen more than not.
Are you sure about that? It will trigger only for what the LLM declares important, not what you care about.
Is anyone delivering local LLMs that can actually be trained on your data? Or just pre made models for the lowest common denominator?
I agree this would be a great use of LLMs! However, it would have to be really low latency, like on the order of milliseconds. I don't think the tech is there yet, although maybe it will be soon-ish.
Google isn’t running ads on TV for Google Docs touting that it uses conflict-free replicated data types, or whatever, because (almost entirely) no one cares. Most people care the same amount about “AI” too.
Ideally, in my view, is that the browser asks you if you are sure regardless of content.
I use LLMs, but that browser "are you sure" type of integration is adding a massive amount of work to do something that ultimately isn't useful in any real way.
It’s already there for Apple developers: https://developer.apple.com/documentation/foundationmodels
I saw some presentations about it last year. It’s extremely easy to use.
I don't think an NPU has that capability.
This AI summer is really kind of a replay of the last AI summer. In a recent story about expert systems seen here on Hackernews, there was even a description of Gary Kildall from The Computer Chronicles expressing skepticism about AI that parallels modern-day AI skepticism. LLMs and CNNs will, as you describe, settle into certain applications where they'll be profoundly useful, become embedded in other software as techniques rather than an application in and of themselves... and then we won't call them AI. Winter is coming.
I've seen people argue that the goalposts keep moving with respect to whether or not something is considered AI, but that's because you can argue that a lot of things computers do are artificial intelligence. Once something becomes commonplace and well understood, it's not useful to communicate about it as AI.
I don't think the term AI will "stick" to a given technology until AGI (or something close to it).
No idea if they are AI Netflix doesn't tell and I don't ask.
AI is just a toxic brand at this point IMO.
https://en.wikipedia.org/wiki/Netflix_Prize
It doesn’t fix the content problem these days though.
Consumer AI has never really made any sense. It's going to end up in the same category of things as 3D TV's, smart appliances, etc.
With more of the compute being pushed off of local hardware they can cheapen out on said hardware with smaller batteries, fewer ports and features, and weaker CPUs. This lessens the pressure they feel from consumers who were taught by corporations in the 20th century that improvements will always come year over year. They can sell less complex hardware and make up for it with software.
For the hardware companies it's all rent seeking from the top down. And the push to put "AI" into everything is a blitz offensive to make this impossible to escape. They just need to normalize non-local computing and have it succeed this time, unlike when they tried it with the "cloud" craze a few years ago. But the companies didn't learn the intended lesson last time when users straight up said that they don't like others gatekeeping the devices they're holding right in their hands. Instead the companies learned they have to deny all other options so users are forced to acquiesce to the gatekeeping.
It's all optics, it's all grift, it's all gambling.
I don't want AI involved in my laundry machines. The only possible exception I could see would be some sort of emergency-off system, but I don't think that even needs to be "AI". But I don't want AI determining when my laundry is adequately washed or dried; I know what I'm doing, and I neither need nor want help from AI.
I don't want AI involved in my cooking. Admittedly, I have asked ChatGPT for some cooking information (sometimes easier than finding it on slop-and-ad-ridden Google), but I don't want AI in the oven or in the refrigerator or in the stove.
I don't want AI controlling my thermostat. I don't want AI controlling my water heater. I don't want AI controlling my garage door. I don't want AI balancing my checkbook.
I am totally fine with involving computers and technology in these things, but I don't want it to be "AI". I have way less trust in nondeterministic neural network systems than I do in basic well-tested sensors, microcontrollers, and tiny low-level C programs.
Have some half decent model integrated with OS's builtin image editing app so average user can do basic fixing of their vacation photos by some prompts
Have some local model with access to files automatically tag your photos, maybe even ask some questions and add tags based on that and then use that for search ("give me photo of that person from last year's vacation"
Similarly with chat records
But once you start throwing it in cloud... people get anxious about their data getting lost, or might not exactly see the value in subscription
On the other hand everyone non-technical I know under 40 uses LLMs and my 74 year old dad just started using ChatGPT.
You could use a search engine and hope someone answered a close enough question (and wade through the SEO slop), or just get an AI to actually help you.
People have more or less converged on what they want on a desktop computers in the last ~30 years. I'm not saying that there isn't room for improvement, but I am saying that I think we're largely at the state of "boring", and improvements are generally going to be more incremental. The problem is that "slightly better than last year" really isn't a super sexy thing to tell your shareholders. Since the US economy has basically become a giant ponzi scheme based more on vibes than actual solid business, everything sort of depends on everything being super sexy and revolutionary and disruptive at all times.
As such, there are going to be many attempts from companies to "revolutionize" the boring thing that they're selling. This isn't inherently "bad", we do need to inject entropy into things or we wouldn't make progress, but a lazy and/or uninspired executive can try and "revolutionize" their product by hopping on the next tech bandwagon.
We saw this nine years ago with "Long Blockchain Ice Tea" [1], and probably way farther back all the way to antiquity.
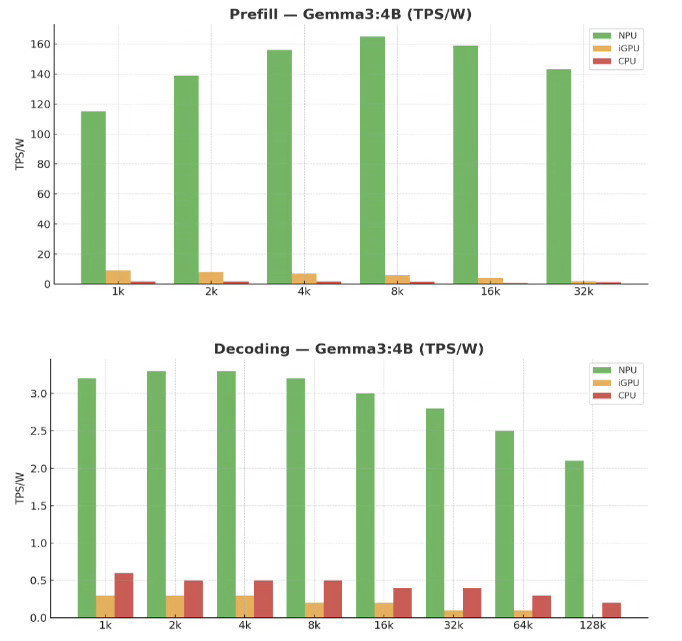
NPUs can be useful for some cases. The AI PC crap is ill thought out however.
But yeah, NPUs likely will be faster.
Does it have a command line utility I can embed into my scripts?
Yes, if you check their community integrations section on faster-whisper [1], you can see a lot of different CLIs, GUIs, and libraries. I recommend WhisperX [2], it's the most complete CLI so far and has features like diarization which whisper.cpp does not have in a production-ready capacity.
[0] https://github.com/SYSTRAN/faster-whisper#benchmark
[1] https://github.com/SYSTRAN/faster-whisper#community-integrat...
They've been vastly ahead of everyone else with things like text OCR, image element recognition / extraction, microphone noise suppression, etc.
iPhones have had these features 2-5 years before Android did.
apple is so hit or miss.
I think the image ocr is great and usable. I can take a picture of a phone number and dial it.
but trying to edit a text field is such a nightmare.
(try to change "this if good" to "this is good" on iphone with your fingers is non-apple cumbersome)
"first" isn't always more important than "best". Apple has historically been ok with not being first, as long as it was either best or very obviously "much better". It always, well, USED TO focus on best. It has lost its way in that lately.
People should not be using their phones while driving anyways. My iPhone disables all notifications, except for Find My notifications, while driving. Bluetooth speaker calls are an exception.
I think there's even better models now but Whisper still works fine for me. And there's a big ecosystem around it.
The only thing that Apple is really behind on is shoving the word (word?) "AI" in your face at every moment when ML has been silently running in many parts of their platforms well before ChatGPT.
Sure we can argue about Siri all day long and some of that is warranted but even the more advanced voice assistants are still largely used for the basics.
I am just hoping that this bubble pops or the marketing turns around before Apple feels "forced" to do a copilot or recall like disaster.
LLM tech isn't going away and it shouldn't, it has its valid use cases. But we will be much better when it finally goes back into the background like ML always was.
- truck drivers that are driving for hours.
- commuters driving to work
- ANYONE with a homepod at home that likes to do things hands free (cooking, dishes, etc).
- ANYONE with airpods in their ears that is not in an awkward social setting (bicycle, walking alone on the sidewalk, on a trail, etc)
every one of these interaction modes benefits from a smart siri.
That’s just the tip of the iceberg. Why can’t I have a siri that can intelligently do multi step actions for me? “siri please add milk and eggs to my Target order. Also let my wife know that i’ll pick up the order on my way home from work. Lastly, we’re hosting some friends for dinner this weekend. I’m thinking Italian. Can you suggest 5 recipes i might like? [siri sends me the recipes ASYNC after a web search]”
All of this is TECHNICALLY possible. There’s no reason apple couldn’t build out, or work with, various retailers to create useful MCP-like integrations into siri. Just omit dangerous or destructive actions and require the user to manually confirm or perform those actions. Having an LLM add/remove items in my cart is not dangerous. Importantly, siri should be able to do some tasks for me in the background. Like on my mac…i’m able to launch Cursor and have it work in agent mode to implement some small feature in my project, while i do something else on my computer. Why must i stare at my phone while siri “thinks” and replies with something stupid lol. Similarly, why can’t my phone draft a reply to an email ASYNC and let me review it later at my leisure? Everything about siri is so synchronous. It sucks.
It’s just soooo sooo bad when you consider how good it could be. I think we’re just conditioned to expect it to suck. It doesn’t need to.
Woah woah woah, surely you’re not suggesting that you, a user, should have some agency over how you interact with a store?
No, no, you’re not getting off that easy. They’ll want you to use Terry, the Target-AI, through the target app.
I have a several homepods, and it does what I ask it to do. This includes being the hub of all of my home automation.
Yes there are areas it can improve but I think the important question is how much use would those things actually get vs making a cool announcement, a fun party trick, and then never used again.
We have also seen the failures that have been done by trying to treat LLM as a magic box that can just do things for you so while these things are "Technically" possible they are far from being reliable.
We are looking forward to being able to ask Siri to pipe some speech through to an AI
To be fair, they did announce flashy AI features. They just didn't deliver them after people bought the products.
I've been reading about possible class action lawsuits and even the government intervening for false advertisement.
For me, the Copilot key outputs the chord "Win (Left) + Shift (Left) + F23". I remapped it to "Ctrl (Right)" and it's functioning as it should.
What is an NPU? Oh it's a special bit of hardware to do AI. Oh ok, does it run ChatGPT? Well no, that still happens in the cloud. Ok, so why would I buy this?
It's quite similar with Apple's neural engine, which afiak is used very little for LLMs, even for coreML. I know I don't think I ever saw it being used in asitop. And I'm sure whatever was using it (facial recognition?) could have easily ran on GPU with no real efficiency loss.
Today, typical consumers aren't even using a ton of AI or enough to even make them think to buy specialized hardware for it. Maybe that changes but it's the current state.
Of course MMX was widely used later but at the time it was complete marketing.
The same workloads could use the GPU but it's more general purpose and thus uses more power for the same task. The same reason macOS uses hardware acceleration for video codecs and even JPEG, the work could be done on the CPU but cost more in terms of power. Using hardware acceleration helps with the 10+ hour lifetime on the battery.
You still need a GPU regardless if you can do JPEG and h264 decode on the card - for games, animations, etc etc.
Your macbook's NPU is probably active every moment that your computer is on, and you just didn't know about it.
You can use asitop to see how often it's actually being used.
I'm not saying it's not ever used, I'm saying it's used so infrequently that any (tiny) efficiency gains do not trade off vs running it on the GPU.
If you're going to be doing ML at the edge, NPUs still seem like the most efficient use of die space to me.
In the end it was faster, cheaper, and more reliable to buy a fat server running our models and pay the bandwidth tax.
One day it will be very cool to run something like ChatGPT, Claude, or Gemini locally in our phones but we're still very, very far away from that.
There is useful functionality there. Apple has had it for years, so have others. But at the time they weren’t calling it “AI“ because that wasn’t the cool word.
I also think most people associate AI with ChatGPT or other conversational things. And I’m not entirely sure I want that on my computer.
But some of the things Apple and others have done that aren’t conversational are very useful. Pervasive OCR on Windows and Mac is fantastic, for example. You could brand that as AI. But you don’t really need to no one cares if you do or not.
I agree. Definitely useful features but still a far cry from LLMs which is what the average consumer identifies as AI.
Unfortunately investors are not ready to hear that yet...
I can see a trend of companies continuing to use AI, but instead portraying it to consumers as "advanced search", "nondeterministic analysis", "context-aware completion", etc - the things you'd actually find useful that AI does very well.
Anyone technical enough to jump into local AI usage can probably see through the hardware fluff, and will just get whatever laptop has the right amount of VRAM.
They are just hoping to catch the trend chasers out, selling them hardware they won't use, confusing it as a requirement for using ChatGPT in the browser.
But when I come on HN and see people posting about AI IDEs and vibe coding and everything, I'm led to believe that there are developers that like this sort of thing.
I cannot explain this.
But the fact remains that I'm producing something for a machine to consume. When I see people using AI to e.g. write e-mails for them that's where I object: that's communication intended for humans. When you fob that off onto a machine something important is lost.
It's okay, you'll just forget you were ever able to know your code :)
But I wasn't talking about forgetting one language or another, i was talking about forgetting to program completely.
That usually means you're missing something, not that everyone else is.
The guy coding in C++ still has a great job, he didnt miss anything, is all fucking FOMO.
I've also had luck with it helping with debugging. It has the knowledge of the entire Internet and it can quickly add tracing and run debugging. It has helped me find some nasty interactions that I had no idea were a thing.
AI certainly has some advantages in certain use cases, that's why we have been using AI/ML for decades. The latest wave of models bring even more possibilities. But of course, it also brings a lot of potential for abuse and a lot of hype. I, too, all quite sick of it all and can't wait for the bubble to burst so we can get back to building effective tools instead of making wild claims for investors.
"This package has been removed, grep for string X and update every reference in the entire codebase" is a great conservative task; easy to review the results, and I basically know what it should be doing and definitely don't want to do it.
"Here's an ambiguous error, what could be the cause?" sometimes comes up with nonsense, but sometimes actually works.
I never use LLMs
this is their aim, along with rabbiting on about "inevitability"
once you drop out of the SF/tech-oligarch bubble the advocacy drops off
It literally has a warning that displays every time you start the car: "Watching this screen and making selections while driving can lead to serious accidents". Then you have to press agree before you can use the A/C or stereo.
Like oh attempting to turn the air conditioner on in your car can lead to serious accidents? Maybe you should rethink your dashboard instead of pasting a warning absolving you of its negative effects?
It also looks like names are being changed, and the business laptops are going with a dell pro (essential/premium/plus/max) naming convention.
Consumer PCs and hardware are going to be expensive in 2026 and AI is primarily to blame. You can find examples of CEOs talking about buying up hardware for AI without having a datacenter to run it in. This run on hardware will ultimately drive hardware prices up everywhere.
The knock on effect is that hardware manufacturers are likely going to spend less money doing R&D for consumer level hardware. Why make a CPU for a laptop when you can spend the same research dollars making a 700 core beast for AI workloads in a datacenter? And you can get a nice premium for that product because every AI company is fighting to get any hardware right now.
You might be right, but I suspect not. While the hardware company are willing to do without laptop sales, data centers need the power efficiency as well.
Facebook has (well had - this was ~10 years ago when I heard it) a team of engineers making their core code faster because in some places a 0.1% speed improvement across all their servers results in saving hundreds of thousands of dollars per month (sources won't give real numbers but reading between the lines this seems about right) on the power bill. Hardware that can do more with less power thus pays for itself very fast in the data center.
Also cooling chips internally is often a limit of speed, so if you can make your chip just a little more efficient it can do more. Many CPUs will disable parts of the CPU not in use just to save that heat, if you can use more of the CPU that translates to more work done and in turn makes you better than the competition.
Of course the work must be done, so data centers will sometimes have to settle for whatever they can get. Still they are always looking for faster chips that use less power because that will show up on the bottom line very fast.
I think a lot of the hardware of these "AI" servers will rather get re-purposes for more "ordinary" cloud applications. So I don't think your scenario will happen.
Do consumers understand that OEM device price increases are due to AI-induced memory price spike over 100%?
Consumers consciously choosing to play games - or serious CAD/image/video editing - usually note they will want a better GPU.
Consumers consciously choosing to use AI/llm? That's a subscription to the main players.
I personally would like to run local llm. But this is far from a mainstream view and what counts as an AI PC now isn't going to cut it.
At CES this year, one of the things that was noted was that "AI" was not being pushed so much as the product, but "things with AI" or "things powered by AI".
This change in messaging seems to be aligning with other macro movements around AI in the public zeitgeist (as AI continues to later phases of the hyper curve) that the companies' who've gone all-in on AI are struggling to adapt to.
The end-state is to be seen, but it's clear that the present technology around AI has utility, but doesn't seem to have enough utility to lift off the hype curve on an continuously upward slope.
Dell is figuring this out, Microsoft is seeing it in their own metrics, Apple and AWS has more or less dipped toes in the pool...I'd wager that we'll see some wild things in the next few years as these big bets unravel into more prosaic approaches that are more realistically aligned with the utility AI is actually providing.
Dell, Dell Pro, Dell Premium, Dell _Pro_ Premium Dell Max, Dell _Pro_ max... They went and added capacitive keys on the XPS? Why would you do this...
A lot of decisions that do not make sense to me.
Sure, the original numbering system did make sense, but you had to Google what the system meant. Now, it's kind of intuitive, even though the it's just a different permutation of the same words?
I've shied away from Dell for a bit because I had two XPS 15's that had swelling batteries. But the new machines look pretty sweet!
All I remember is having all sorts of fun trying to get those keys to work at all in Linux; they often were insanely setup and dependent on windows drivers (some would send a combination keystroke, some wouldn't work unless polled, etc).
--------------
What we're seeing here is that "AI" lacks appeal as a marketing buzzword. This probably shouldn't be surprising. It's a term that's been in the public consciousness for a very long time thanks to fiction, but more frequently with negative connotations. To most, AI is Skynet, not the thing that helps you write a cover letter.
If a buzzword carries no weight, then drop it. People don't care if a computer has a NPU for AI any more than they care if a microwave has a low-loss waveguide. They just care that it will do the things they want it to do. For typical users, AI is just another algorithm under the hood and out of mind.
What Dell is doing is focusing on what their computers can do for people rather than the latest "under the hood" thing that lets them do it. This is probably going to work out well for them.
I actually do care, on a narrow point. I have no use for an NPU and if I see that a machine includes one, I immediately think that machine is overpriced for my needs.
Does anyone know: How do these vendors (like Dell) think normie retail buyers would use their NPUs?
Hence the large percentage of Youtube ads I saw being "with a Dell AI PC, powered by Intel..." here are some lies.
> Any computer running nonfree software can't be a personal one
Making consumers want things is fixable in any number of ways.
Tariffs?..
Supply chain issues in a fracturing global order?..
.. not so much. Only a couple ways to fix those things, and they all involve nontrivial investments.
Even longer term threats are starting to look more plausible these days.
Lot of unpredictability out there at the moment.
On Linux it does nothing, on Windows it tells me I need an Office 365 plan to use it.
Like... What the hell... They literally placed a paywalled Windows only physical button on my laptop.
What next, an always-on screen for ads next to the trackpad?
I'm serious. They dropped the Office branding and their office suite is now called Copilot.
This is good news because it means the Copilot button opens Copilot, which is exactly what you'd expect it to do.
Local speech recognition is genuinely useful and much more private than server based options.
But I use the 3Gb all day every day.
I built a personal voice agent
Some useful applications do exist. Particularly grammar checkers and I think windows recall could be useful. But we don't currently have these designed well such that it makes sense.
They have something called the Windows Copilot Runtime but that seems to be a blanket label and from their announcement I couldn't really figure out how the NPU ties into it. It seems like the NPU is used if it's there but isn't necessary for most things.
I remember when LLMs were taking off, and open-weight were nipping at the heels of frontier models, people would say there's no moat. The new moat is high bandwidth RAM as we can see from the recent RAM pricing madness.
This does not fit my observation. It's rather that running one's local LLM is currently far too complicated for the average PC user.
They just want a good PC that runs Word and Excel and likely find the fact that Copilot keeps popping up in Word every time they open a new document to be annoying rather than helpful.
The return back to physical buttons makes the XPS look pretty appealing again.
I love my 2020 XPS.
The keyboard keys on mine do not rattle, but I have seen newer XPS keyboard keys that do rattle. I hope they fixed that.
But we've been there before. Computers are going to get faster for cheaper, and LLMs are going to be more optimized, cause right now, they do a ton of useless calculations for sure.
There's a market, just not right now.
That being said, netflix would be an impossible app without gfx acceleration APIs that are enabled by specific CPU and/or GPU instruction sets. The typical consumer doesn't care about those CPU/GPU instruction sets. At least they don't care to know about them. However they would care if they didn't exist and Netflix took 1 second per frame to render.
Similar to AI - they don't care about AI until some killer app that they DO care about needs local AI.
There is no such killer app. But they're coming. However as we turn the corner into 2026 it's becoming extremely clear that local AI is never going to be enough for the coming wave of AI requirements. AI is going to require 10-15 simultaneous LLM calls or GenAI requests. These are things that won't do well on local AI ever.
I wouldn't hate this so much if it was just a labeling thing. Unfortunately, MSFT changed how that key works at a low level so it cannot be cleanly remapped back to right-CTRL. This is because, unlike the CTRL, ALT, Shift and Windows keys, the now-CoPilot key no longer behaves like a modifier key. Now when you press the CoPilot key down it generates both key down and key up events - even when you keep it pressed down. You can work around this somewhat with clever key remapping in tools like AutoHotKey but it is literally impossible to fully restore that key back so it will behave like a true modifier key such as right-CTRL in all contexts. There are a limited number of true modifier keys built into a laptop. Stealing one of them to upsell a monetized service is shitty but intentionally preventing anyone from being able to restore it goes beyond shitty to just maliciously evil.
More technical detail: The CoPilot key is really sending: Shift+Alt+Win+Ctrl+F23 which Windows now uses as the shortcut to run the CoPilot application. When you remap the CoPilot key to right-Ctrl only the F23 is being remapped to right-Ctrl. Due to the way Windows works and because MSFT is now sending F23 DOWN and then F23 UP when the CoPilot key has only been pressed Down but not yet released, those other modifiers remain pressed down when our remapped key is sent. I don't know if this was intentional on MSFT's part to break full remapping or if it's a bug. Either way, it's certainly non-standard and completely unnecessary. It would still work for calling the CoPilot app to wait for the CoPilot key to be released to send the F23 KEY UP event. That's the standard method and would allow full remapping of the key.
But instead, when you press CoPilot after remapping it to Right-Ctrl... the keys actually being sent are: Shift+Alt+Win+Right-Ctrl (there are also some other keypresses in there that are masked). If your use case doesn't care that Shift, Alt and Win are also pressed with Right-Ctrl then it'll seem fine - but it isn't. Your CoPilot key remapped to Right-Ctrl no longer works like it did before or like Left-Ctrl still works (sending no other modifiers). Unfortunately, a lot of shortcuts (including several common Windows desktop shortcuts) involve Ctrl in combination with other modifiers. Those shortcuts still work with Left-Ctrl but not CoPilot remapped to Right-Ctrl. And there's no way to fix it with remapping (whether AutoHotKey, PowerToys, Registry Key, etc). It might be possible to fix it with a service running below the level of Windows with full admin control which intercepts the generated keys before Windows ever sees them - but as far as I know, no one has succeeded in creating that.
> "We're very focused on delivering upon the AI capabilities of a device—in fact everything that we're announcing has an NPU in it—but what we've learned over the course of this year, especially from a consumer perspective, is they're not buying based on AI," Terwilliger says bluntly. "In fact I think AI probably confuses them more than it helps them understand a specific outcome."
He's talking about marketing. They're still gonna shove it into anything and everything they can. They just aren't gonna tell you about it.
Now, for some who actually want to do AI locally, they are not going to look for "AI PCs". They are going to look for specific hardware, lots of RAM, big GPUs, etc... And it is not a very common use case anyways.
I have an "AI laptop", and even I, who run a local model from time to time and bought that PC with my own money don't know what it means, probably some matrix multiplication hardware that I have not idea how to take advantage of. It was a good deal for the specs it had, that's the only thing I cared for, the "AI" part was just noise.
At least a "gaming PC" means something. I expect high power, a good GPU, a CPU with good single-core performance, usually 16 to 32 GB of RAM, high refresh rate monitor, RGB lighting. But "AI PC", no idea.
This seems like a cop out for saving cost by putting Intel GPUs in laptops instead of Nvidia.
{kind=link}