Working for free is not fun. Having a paid offering with a free community version is not fun. Ultimately, dealing with people who don't pay for your product is not fun. I learnt this the hard way and I guess the MinIO team learnt this as well.
I highly recommend SeaweedFS. I used it in production for a long time before partnering with Wasabi. We still have SeaweedFS for a scorching hot, 1GiB/s colocated object storage, but Wasabi is our bread and butter object storage now.
> Completely different situations. None of the MinIO team worked for free. MinIO is a COSS company (commercial open source software).
MinIO is dealing with two out of the three issues, and the company is partially providing work for free, how is that "completely different"?
You could argue that they got to the point where the benefit wasn’t worth the cost, but this was their business model. They would not have gotten to the point where the could have a commercial-only operation without the adoption and demand generated from the OSS version.
Running a successful OSS project is often a thankless job. Thanks for doing it. But this isn’t that.
No, even if you are being paid, it's a thankless, painful job to deal with demanding, entitled free users. It worse if you are not being paid, but I'm not sure why you are asserting dealing with bullshit is just peachy if you are being paid.
Any recommendation for an in-cluster alternative in production?
Is that SeaweedFS?
It’s used by CERN to make Petabyte-scale storage capable of ingesting data from particle collider experiments and they're now up to 17 clusters and 74PB which speaks to its production stability. Apparently people use it down to 3-host Proxmox virtualisation clusters, in a similar place as VMware VSAN.
Ceph has been pretty good to us for ~1PB scalable backup storage for many years, except that it’s a non-trivial system administration effort and needs good hardware and networking investment, and my employer wasn't fully backing that commitment. (We’re moving off it to Wasabi for S3 storage). It also leans more towards data integrity than performance, it's great at being massively-parallel and not so rapid at being single thread high-IOPs.
https://ceph.io/en/users/documentation/
https://docs.ceph.com/en/latest/
https://indico.cern.ch/event/1337241/contributions/5629430/a...
Did minio create the impression to its contributors that it will continue being FLOSS?
Just be honest since the start that your product will eventually abandon its FOSS licence. Then people can make an informed decision. Or, if you haven't done that, do the right thing and continue to stand by what you originally promised.
But FOSS means “this particular set of source files is free to use and modify”. It doesn’t include “and we will forever keep developing and maintaining it forever for free”.
It’s only different if people, in addition to the FOSS license, promise any further updates will be under the same license and then change course.
And yes, there is a gray area where such a promise is sort-of implied, but even then, what do you prefer, the developers abandoning the project, or at least having the option of a paid-for version?
License terms don't end there. There is a no warranty clause too in almost every open source license and it is as important as the other parts of the license. There is no promise or guarantees for updates or future versions.
I think this is where the problem/misunderstanding is. There's no "I will do/release" in OSS unless promised explicitly. Every single release/version is "I released this version. You are free to use it". There is no implied promise for future versions.
Released software is not clawed back. Everyone is free to modify(per license) and/or use the released versions as long as they please.
While I agree with the sentiment, keep in mind that circumstances change over the years. What made sense (and what you've believed in) a few years ago may be different now. This is especially true when it comes to business models.
When backed by a company there is an ethical obligation to keep, at least maintenance. Of course legally they can do what they wish. It isn't unfair to call it bad practice.
Having a FOSS license is NOT enough. Idealy the copyright should be distributed across all contributors. That's the only way to make overall consensus a required step before relicensing (except for reimplementation).
Pick FOSS projects without CLAs that perform Copyright Assignment to an untrusted entity (few exceptions apply, e.g. the FSF in the past)
Hoes does this look? How does one "just" do this? What if the whole thing was an evolution over time?
"An informed decision" is not a black or white category, and it definitely isn't when we're talking about risk pricing for B2B services and goods, like what MinIO largely was for those who paid.
Any business with financial modelling worth their salt knows that very few things which are good and free today will stay that way tomorrow. The leadership of a firm you transact with may or may not state this in words, but there are many other ways to infer the likelihood of this covertly by paying close attention.
And, if you're not paying close attention, it's probably just not that important to your own product. What risks you consider worth tailing are a direct extension of how you view the world. The primary selling point of MinIO for many businesses was, "it's cheaper than AWS for our needs". That's probably still true for many businesses and so there's money to be made at least in the short term.
Like with software development, we often lack the information on which we have to decide architectural, technical or business decisions.
The common solution for that is to embrace this. Defer decisions. Make changing easy once you do receive the information. And build "getting information" into the fabric. We call this "Agile", "Lean", "data driven" and so on.
I think this applies here too.
Very big chance that MinIO team honestly thought that they'd keep it open source but only now gathered enough "information" to make this "informed decision".
What it fails to recognize is the reality that life changes. Shit happens. There's no way to predict the future when you start out building an open source project.
(Coming from having contributed to and run several open source projects myself)
When you start something (startup, FOSS project, damn even marriage) you might start with the best intentions and then you can learn/change/loose interest. I find it unreasonable to "demand" clarity "at the start" because there is no such thing.
Turning it around, any company that adopts a FOSS project should be honest and pay for something if it does not accept the idea that at some point the project will change course (which obviously, does not guarantee much, because even if you pay for something they can decide to shut it down).
Obviously you cannot "demand" stuff but you can do your due dilligence as the person who chooses a technical solution. Some projects have more clarity than others, for example the Linux foundation or CNCF are basically companies sharing costs for stuff they all benefit from like Linux or Prometheus monitoring and it is highly unlikely they'd do a rug pull.
On the other end of the spectrum there are companies with a "free" version of a paid product and the incentive to make the free product crappier so that people pay for the paid version. These should be avoided.
FOSS is not a moral contract. People working for free owe nothing to no one. You got what's on the tin - the code is as open source once they stop as when they started.
The underlying assumption of your message is that you are somehow entitled to their continued labour which is absolutely not the case.
Free users certainly would like it to be a social contract like I would like to be gifted a million dollars. Sadly, I still have to work and can't infinitely rely on the generosity of others.
Free software developers are gifting you something. Expecting indefinite free work is not mutual respect. That's entitlement.
The common is still there. You have the code. Open source is not a perpetual service agreement. It is not indentured servitude to the community.
Stop trying to guilt trip people into giving you free work.
Nobody sensible is upset when a true FOSS “working for free” person hangs up their boots and calls it quits.
The issue here is that these are commercial products that abuse the FOSS ideals to run a bait and switch.
They look like they are open source in their growth phase then they rug pull when people start to depend on their underlying technology.
The company still exists and still makes money, but they stopped supporting their open source variant to try and push more people to pay, or they changed licenses to be more restrictive.
It has happened over and over, just look at Progress Chef, MongoDB, ElasticSearch, Redis, Terraform, etc.
Is it really though? They're replacing one product with another, and the replacement comes with a free version.
I use a few simple heuristics:
- Evaluate who contributes regularly to a project. The more diverse this group is, the better. If it's a handful of individuals from 1 company, see other points. This doesn't have to be a show stopper. If it's a bit niche and only a handful of people contribute, you might want to think about what happens when these people stop doing that (like is happening here).
- Look at required contributor agreements and license. A serious red flag here is if a single company can effectively decide to change the license at any point they want to. Major projects like Terraform, Redis, Elasticsearch (repeatedly), etc. have exercised that option. It can be very disruptive when that happens.
- Evaluate the license allows you do what you need to do. Licenses like the AGPLv3 (which min.io used here) can be problematic on that front and comes with restrictions that corporate legal departments generally don't like. In the end choosing to use software is a business decision you take. Just make sure you understand what you are getting into and that this is OK with your company and compatible with business goals.
- Permissive licenses (MIT, BSD, Apache, etc.) are popular with larger companies and widely used on Github. They facilitate a neutral ground for competitors to collaborate. One aspect you should be aware off is that the very feature that makes them popular also means that contributors can take the software and create modifications under a different license. They generally can't re-license existing software or retroactively. But companies like Elasticsearch have switched from Apache 2.0 to closed source, and recently to AGPLv3. Opensearch remains Apache 2.0 and has a thriving community at this point.
- Look at the wider community behind a project. Who runs it; how professional are they (e.g. a foundation), etc. How likely would it be to survive something happening to the main company behind a thing? Companies tend to be less resilient than the open source projects they create over time. They fail, are subject to mergers and acquisitions, can end up in the hands of hedge funds, or big consulting companies like IBM. Many decades old OSS projects have survived multiple such events. Which makes them very safe bets.
None of these points have to be decisive. If you really like a company, you might be willing to overlook their less than ideal licensing or other potential red flags. And some things are not that critical if you have to replace them. This is about assessing risk and balancing the tradeoff of value against that.
Forks are always an option when bad things happen to projects. But that only works if there's a strong community capable of supporting such a fork and a license that makes that practical. The devil is in the details. When Redis announced their license change, the creation of Valkey was a foregone conclusion. There was just no way that wasn't going to happen. I think it only took a few months for the community to get organized around that. That's a good example of a good community.
most projects won't ever reach that level though.
OP sure makes it sound like it's about the money.
> for someone that just wants to put code out there that is very draining and unpleasant.
I never understood this. Then why publish the code in the first place? If the goal is to help others, then the decent thing would be to add documentation and support the people who care enough to use your project. This doesn't mean bending to all their wishes and doing work you don't enjoy, but a certain level of communication and collaboration is core to the idea of open source. Throwing some code over the fence and forgetting about it is only marginally better than releasing proprietary software. I can only interpret this behavior as self-serving for some reason (self-promotion, branding, etc.).
Then the third user shows up. They have an odd edge case and the code isn't working. Fixing it will take some back and forth but it still can be done in a respectable amount of time. All is good. A few more users might show up, but most open source projects will maintain a small audience. Everyone is happy.
Sometimes, projects keep gaining popularity. Slowly at first, but the growth in interest is there. More bug reports, more discussions, more pull requests. The author didn't expect it. What was doable before takes more effort now. Even if the author adds contributors, they are now a project and a community manager. It requires different skills and a certain mindset. Not everyone is cut out for this. They might even handle a small community pretty well, but at a certain size it gets difficult.
The level of communication and collaboration required can only grow. Not everyone can deal with this and that's ok.
There is obligation to a given user only if it's explicitly specified in a license or some other communication to which the user is privy.
> but a certain level of communication and collaboration is core to the idea of open source.
Because these things take entirely different skill sets and the latter might be a huge burden for someone who is good at the former.
I find it the other way around. I feel a bit embarrassed and stressed out working with people who have paid for a copy of software I've made (which admittedly is rather rare). When they haven't paid, every exchange is about what's best for humanity and the public in general, i.e. they're not supposed to get some special treatment at the expense of anyone else, and nobody has a right to lord over the other party.
As DHH and Jason Fried discuss in both the books REWORK, It Doesn’t Have to Be Crazy at Work, and their blog:
> The worst customer is the one you can’t afford to lose. The big whale that can crush your spirit and fray your nerves with just a hint of their dissatisfaction.
(It Doesn’t Have to Be Crazy at Work)
> First, since no one customer could pay us an outsized amount, no one customer’s demands for features or fixes or exceptions would automatically rise to the top. This left us free to make software for ourselves and on behalf of a broad base of customers, not at the behest of any single one. It’s a lot easier to do the right thing for the many when you don’t fear displeasing a few super customers could spell trouble.
(https://signalvnoise.com/svn3/why-we-never-sold-basecamp-by-...)
But, this mechanism proposed by DHH and Fried only remove differences amongst the paying-customers. I Not between "paying" and "non-paying".
I'd think, however, there's some good ideas in there to manage that difference as well. For example to let all the customers, paying- or not-paying go through the exact same flow for support, features, bugs, etc. So not making these the distinctive "drivers" why people would pay. E.g. "you must be paying customer to get support". Obviously depends on the service, but maybe if you have other distinctive features that people would pay for (e.g. hosted version) that could work out.
However, I understood GP's mention of "embarrassment" to speak more to their own feelings of responsibility. Which would be more or less decoupled from the pressure that a particular client exerts.
People who don't pay are often not really invested. The relationship between more work means more costs doesn't exist for them. That can make them quite a pain in my experience.
> every exchange is about what's best for humanity and the public in general
it means that they are the kind of individual who deeply care for things to work, relationships to be good and fruitful and thus if they made someone pay for something, they think they must listen to them and comply their requests, because well, they are a paying customer and the customer is always right, they gave me their money etc etc
You can care about the work and your customer will still setting healthy boundaries and accepting that wanting to do good work for them doesn't mean you are beside them.
Business is fundamentally about partnership, transactional and moneyed partnerships, but partnership still. It's best when both suppliers and customers are aware of that and like any partnership, it structured and can be stopped by both partners. You don't technically owe them more than what's in the contract and that puts a hard stop which is easy to identify if needed.
Users of open source often feel entitled, open issues like they would open a support ticket for product they actually paid for, and don't hesitate to show their frustration.
Of course that's not all the users, but the maintainers only see those (the happy users are usually quiet).
I have open sourced a few libraries under a weak copyleft licence, and every single time, some "people from the community" have been putting a lot of pressure on me, e.g. claiming everywhere that the project was unmaintained/dead (it wasn't, I just was working on it in my free time on a best-effort basis) or that anything not permissive had "strings attached" and was therefore "not viable", etc.
The only times I'm not getting those is when nobody uses my project or when I don't open source it. I have been open sourcing less of my stuff, and it's a net positive: I get less stress, and anyway I wasn't getting anything from the happy, quiet users.
It's a trade off, we made it collectively.
This is also true to some extend when it's a project you started. I don't think you should e.g. be able to point to the typical liability disclaimer in free software licenses when you add features that intentionally harm your users.
Good luck with the back pain.
Other alternatives:
https://github.com/deuxfleurs-org/garage
https://github.com/rustfs/rustfs
https://github.com/seaweedfs/seaweedfs
https://github.com/supabase/storage
https://github.com/scality/cloudserver
Among others
https://imgur.com/a/WN2Mr1z (UK: https://files.catbox.moe/m0lxbr.png)
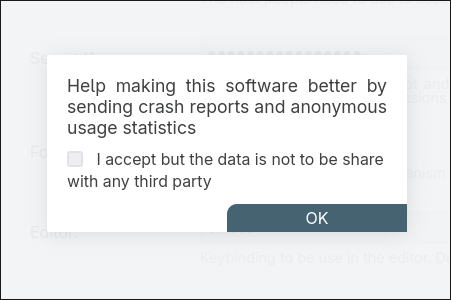
I clicked settings, this appeared, clicking away hid it but now I cant see any setting for it.
The nasty way of reading that popup, my first way of reading it, was that filestash sends crash reports and usage data, and I have the option to have it not be shared with third parties, but that it is always sent, and it defaults to sharing with third parties. The OK is always consenting to share crash reports and usage.
I'm not sure if it's actually operating that way, but if it's not the language should probably be
Help make this software better by sending crash reports and anonymous usage statistics.
Your data is never shared with a third party.
[ ] Send crash reports & anonymous usage data.
[ OK ]They've been active in the Ceph community for a long time.
I don't know any specifics, but I'm pretty sure their Ceph installation is pretty big and used to support critical data.
rustfs have promise, supports a lot of features, even allows to bring your own secret/access keys (if you want to migrate without changing creds on clients) but it's very much still in-development; and they have already prepared for bait-and-switch in code ( https://github.com/rustfs/rustfs/blob/main/rustfs/src/licens... )
Ceph is closest feature wise to actual S3 feature-set wise but it's a lot to setup. It pretty much wants few local servers, you can replicate to another site but each site on its own is pretty latency sensitive between storage servers. It also offers many other features aside, as S3 is just built on top of their object store that can be also used for VM storage or even FUSE-compatible FS
Garage is great but it is very much "just to store stuff", it lacks features on both S3 side (S3 have a bunch of advanced ACLs many of the alternatives don't support, and stuff for HTTP headers too) and management side (stuff like "allow access key to access only certain path on the bucket is impossible for example). Also the clustering feature is very WAN-aware, unlike ceph where you pretty much have to have all your storage servers in same rack if you want a single site to have replication.
There's also a CLA with full copyright assignment, so yeah, I'd steer clear of that one: https://github.com/rustfs/rustfs/blob/main/CLA.md
I run Ceph at work. We have some clusters spanning 20 racks in a network fabric that has over 100 racks.
In a typical Leaf-Spine network architecture, you can easily have sub 100 microsecond network latency which would translate to sub millisecond Ceph latencies.
We have one site that is Leaf-Spine-SuperSpine, and the difference in network latency is barely measurable between machines in the same network pod and between different network pods.
[0]: https://github.com/seaweedfs/seaweedfs/wiki/Quick-Start-with...
Yes I'm looking for exactly that and unfortunately haven't found a solution.
Tried garage, but they require running a proxy for CORS, which makes signed browser uploads a practical impossibility for the development machine. I had no idea that such a simple popular scenario is in fact too exotic.
This was written to store many thousands of images for machine learning
I too think it would be great with a simple project that can serve S3 from filesystem, for local deployments that doesn't need balls to the walls performance.
I'm using seaweedfs for a single-machine S3 compatible storage, and it works great. Though I'm missing out on a lot of administrative nice-to-haves (like, easy access controls and a good understanding of capacity vs usage, error rates and so on... this could be a pebcak issue though).
Ceph I have also used and seems to care a lot more about being distributed. If you have less than 4 hosts for storage it feels like it scoffs at you when setting up. I was also unable to get it to perform amazingly, though to be fair I was doing it via K8S/Rook atop the Flannel CNI, which is an easy to use CNI for toy deployments, not performance critical systems - so that could be my bad. I would trust a ceph deployment with data integrity though, it just gives me that feel of "whomever worked on this, really understood distributed systems".. but, I can't put that feeling into any concrete data.
Let's hope the editor has second thoughts on some parts
I expect rugpull in the future
nice catch.
https:/github.com/beep-industries/content
Overall great philosophy (target at self-hosting / independence) and clear and easy maintenance, not doing anything fancy, easy to understand architecture and design / operation instructions.
Is AIStor Free really free like they claim here https://www.min.io/pricing, i.e
Free
For developers, researchers, enthusiasts, small organizations, and anyone comfortable with a standalone deployment.
Full-featured, single-node deployment architecture
Self-service community Slack and documentation support
Free of charge
It was pretty clear they pivoted to their closed source repo back then.
unless a security issue is reported it does feel very much the same...
If there is a real community around it, forking and maintaining an open edition will be a no-brainer.
Sofar I've switched to Rustfs which seems like a very nice project, though <24hrs is hardly an evaluation period.
Object storage has advantages over regular block storage if it is managed by cloud, and if it has a proven record on durability, availability and "infinite" storage space at low costs, such as S3 at Amazon or GCS at Google.
Object storage has zero advantages over regular block storage if you run it on yourself:
- It doesn't provide "infinite" storage space - you need to regularly monitor and manually add new physical storage to the object storage.
- It doesn't provide high durability and availability. It has lower availability comparing to a regular locally attached block storage because of the complicated coordination of the object storage state between storage nodes over network. It usually has lower durability than the object storage provided by cloud hosting. If some data is corrupted or lost on the underlying hardware storage, there are low chances it is properly and automatically recovered by DIY object storage.
- It is more expensive because of higher overhead (and, probably, half-baked replication) comparing to locally attached block storage.
- It is slower than locally attached block storage because of much higher network latency compared to the latency when accessing local storage. The latency difference is 1000x - 100ms at object storage vs 0.1ms at local block storage.
- It is much harder to configure, operate and troubleshoot than block storage.
So I'd recommend taking a look at other databases for logs, which do not require object storage for large-scale production setups. For example, VictoriaLogs. It scales to hundreds of terabytes of logs on a single node, and it can scale to petabytes of logs in cluster mode. Both modes are open source and free to use.
Disclaimer: I'm the core developer of VictoriaLogs.
Worth adding, this depends on what's using your block storage / object storage. For Loki specifically, there are known edge-cases with large object counts on block storage (this isn't related to object size or disk space) - this obviously isn't something I've encountered & I probably never will, but they are documented.
For an application I had written myself, I can see clearly that block storage is going to trump object storage for all self-hosted usecases, but for 3P software I'm merely administering, I have less control over its quirks & those pros -vs- cons are much less clear cut.
While I try to avoid complexity, idiomatic approaches have their advantages; it's always a trade-off.
That said my first instinct when I saw minio's status was to use filestorage but the rustfs setup has been pretty painless sofar. I might still remove it, we'll see.
On AWS S3, you have a storage level called "Infrequent Access", shortened IA everywhere.
A few weeks ago I had to spend way too much time explaining to a customer that, no, we weren't planning on feeding their data to an AI when, on my reports, I was talking about relying on S3 IA to reduce costs...
Self hosted or just using git itself is only solution
The frustrating part isn't the business decision itself. It's that every pivot creates a massive migration burden on teams who bet on the "open" part. When your object storage layer suddenly needs replacing, that's not a weekend project. You're looking at weeks of testing, data migration, updating every service that touches S3-compatible APIs, and hoping nothing breaks in production.
For anyone evaluating infrastructure dependencies right now: the license matters, but the funding model matters more. Single-vendor open source projects backed by VC are essentially on a countdown timer. Either they find a sustainable model that doesn't require closing the source, or they eventually pull the rug.
Community-governed projects under foundations (Ceph under Linux Foundation, for example) tend to be more durable even if they're harder to set up initially. The operational complexity of Ceph vs MinIO was always the tradeoff - but at least you're not going to wake up one morning to a "THIS REPOSITORY IS NO LONGER MAINTAINED" commit.
While I loath the moves to closed source you also can't fault them the hyperscalers just outcompete them with their own software.
An alternative I've seen is "the code is proprietary for 1 year after it was written, after that it's MIT/GPL/etc.", which keeps the code entirely free(ish) but still prevents many businesses from getting rich off your product and leaving you in the dust.
You could also go for AGPL, which is to companies like Google like garlic is to vampires. That would hurt any open core style business you might want to build out of your project though, unless you don't accept external contributions.
2. You're forgetting bureaucracy and general big company overhead. Hyperscalers have tried to kill a lot of smaller external stuff and frequently they end up their own chat apps, instead.
I struggle to even find example of VC-backed OSS that didn't go "ok closing down time". Only ones I remember (like Gitlab) started with open core model, not fully OSS
From my experience, Ceph works well, but requires a lot more hardware and dedicated cluster monitoring versus something like more simple like Minio; in my eyes, they have a somewhat different target audience. I can throw Minio into some customer environments as a convenient add-on, which I don't think I could do with Ceph.
Hopefully one of the open-source alternatives to Minio will step in and fill that "lighter" object storage gap.
I don't expect free shit forever.
Even plain terminals are now "agentic orchestrators": https://www.warp.dev
Yes.
https://www.theguardian.com/technology/2017/dec/21/us-soft-d...
A Ponzi can be a good investment too (for a certain definition of "good") as long as you get out before it collapses. The whole tech market right now is a big Ponzi with everyone hoping to get out before it crashes. Worse, dissent risks crashing it early so no talks of AI limitations or the lack of actual, sustainable productivity improvements are allowed, even if those concerns do absolutely happen behind closed doors.
"Long Island Iced Tea Corp [...] In 2017, the corporation rebranded as Long Blockchain Corp [...] Its stock price spiked as much as 380% after the announcement."
I've used minio a lot but only as part of my local dev pipeline to emulate s3, and never paid.
garaged:
image: dxflrs/garage:v2.2.0
ports:
- "3900:3900"
- "3901:3901"
- "3902:3902"
- "3903:3903"
volumes:
- /opt/garage/garage.toml:/etc/garage.toml:ro
- /opt/garage/meta:/var/lib/garage/meta
- /opt/garage/data:/var/lib/garage/data1. All filenames are read. 2. All filenames are sorted. 3. Pagination applied.
It doesn't scale obviously, but works ok-ish for a smaller data set. It is difficult to do this efficiently without introducing complexity. My applications don't use listing, so I prioritised simplicity over performance for the list operation.
Listing was IMO a problem with minio as well, but maybe it is not that important because it seems to have succeeded anyway.
They could just archive it there and then, at least it would be honest. What a bunch of clowns.
Unfortunately I don't know of any other open projects that can obviously scale to the same degree. I built up around 100PiB of storage under minio with a former employer. It's very robust in the face of drive & server failure, is simple to manage on bare hardware with ansible. We got 180Gbps sustained writes out of it, with some part time hardware maintenance.
Don't know if there's an opportunity here for larger users of minio to band together and fund some continued maintenance?
I definitely had a wishlist and some hardware management scripts around it that could be integrated into it.
{kind=link}