It's a pity that such a weird artifact/choice has made its way into a branching model that has become so widely implemented. Especially when the rest of it is so sensible - the whole "feature-branch, release-branch, hotfix" flow is IMO exactly right for versioned software where you must support multiple released versions of it in the wild (and probably the reason why it's become so popular). I just wish it didn't have that one weirdness marring it.
Maybe I’m overly cynical but I think git-flow was popular largely because of the catchy name and catchy diagram. When you point out that it has some redundant or counter-productive parts, people push back: “it’s a successful model! It’s standard! What makes you think you can do better?”
There’s a nice write-up of the trunk-based style at https://trunkbaseddevelopment.com/ that you can point to as something better.
It was because Git showed up in the era of SVN / CVS where those branching models were created because of the uh... let's just call it technical mishaps of those source control systems.
Git did not have the hang ups of SVN / CVS / etc but people stuck with what was familiar.
I don't buy this. I've never used git-flow in life. No team I've worked for has ever used git-flow. Yet all of us have been using Git for ages. Git has been hugely successfully independently and different teams follow different Git workflows. Its success has got very little to do with git-flow.
It's not really debatable. Git flow came about because of SVN / CVS practices and was the first and for many still is THE branching model they use.
>Yet all of us have been using Git for ages
You say "all of us" but then you completely ignore the primary branching model the vast, vast majority of people use on Git.
Just for the record, this isn't being stated in support of git-flow it's just a historical fact that's not really debatable.
> it's just a historical fact that's not really debatable.
Over my last 15 years of software dev, I have _never_ heard of anyone actually using Gitflow in their codebase.
I'm not saying you're wrong. My experience is anecdotal. But I don't know why you say it's a "fact". Was there surveys or anything?
Very weird for you to start a reply like this when we are literally debating it.
> You say "all of us"
Yes, I mean those of who don't use git-flow. That's what I meant by "all of us".
> ignore the primary branching model the vast, vast majority of people use on Git.
Do you live in a git-flow bubble or what? I've been using VCS since the dark ages of CVS. Moved to SVN. Mercurial. Git. Never worked in a team using git-flow. Never used git-flow myself. Never met anyone IRL who uses git-flow. I only read about these things on HN and blogs.
What kind of stats do you have to claim that this is the primary branching model. If I go by my experience, it's a minority branching model that only people living within the bubble care about.
> it's just a historical fact that's not really debatable.
What is a historical fact? That people use git-flow. Nobody is contesting that. What I am contesting is that the success of Git is not connected to git-flow like the grand-grand-parent comment said.
I've never seen an organisation that insists on release branches and complicated git merge flows to release their web-based software gain any actual benefit from it that isn't dwarfed by the amount of tooling you need to put around it to make it workable to the dev team, and even then, people will routinely screw it up and need to reach out to the 5% of the team that actually understands the system so they can go back to doing work.
But for continuously deployed SaaS or webapps, there's no point.
This also means that the release to prod happens post-integration by means of turning the feature flag on. Which is arguably a higher quality code review than pre-integration.
Then you can merge to master and it's immediately ready to go.
That's what tags are for, QA tests the tagged release, then that gets released. Master can continue changing up until the next tag, then QA has another thing to test.
Presumably you are maintaining the ordering of these releases with your naming scheme for tags. For instance, using semver tags with your main release being v1.2.0 and your hotfix tag being v1.2.1, even while you've got features in flight for v1.3.0 or v1.4.0 or v2.0.0. Keeping track of the order of versions is part of semver's job.
Perhaps the distinction is that v1.2.0 and v1.2.1 are still separate releases. A bug fix is a different binary output (for compiled languages) and should have its own release tag. Even if you aren't using a compiled language but are using a lot of manual QA, different releases have different QA steps and tracking that with different version numbers is helpful there, too.
What are you trying to achieve here, or what's the crux? I'm not 100% sure, but it seems you're asking about how to apply a bug fix while QA is testing a tag, that you'd like to be a part of the eventual release, but not on top of other features? Or is about something else?
I think one misconception I can see already, is that tags don't belong to branches, they're on commits. If you have branch A and branch B, with branch B having one extra commit and that commit has tag A, once you merge branch B into branch A, the tag is still pointing to the same commit, and the tag has nothing to do with branches at all. Not that you'd use this workflow for QA/releases, but should at least get the point across.
It really depends on the whole development workflow, but in my experience it was always easier and less hassle to develop on the main/master branch and create stable release or fix branch as needed. With that one also prioritizes on fixing on master first and cherry-pick that fix then directly to the stable branch with potential adaptions relevant for the potential older code state there.
With branching of stable branches as needed the git history gets less messy and stays more linear, making it easier to follow and feels more like a "only pay for what you actually use" model.
It sounds like you are doing a monorepo type thing. Git does work best and was designed for multiple/independent repos.
It makes using `git describe` a little bit more complicated, but not that much more complicated. You just need to `--match project-a/` or `--match project-b/` when you want `git describe` for a specific project.
And this is more than just knowing the exact commit. Which, fair, that that is all that you truly need.
Having it on a branch, though, reflects that hot fixes and similar can still be applied, and though the tag will remain at what was released, the branch will be what it currently looks like.
The only meaningfully different model is when you have a continuously-releasable trunk and never do fixes on older releases (quite common for internal tools).
Imagine you have multiple contributors with multiple new features, and you want to do a big release with all of them. You sit down a weekend and merge in your own feature branch, and then tell everyone else to do so too - but it's a hobby project, the other guys aren't consistently available, maybe they need two weekends to integrate and test when they're merging their work with everyone else's, and they don't have time during the weekdays.
So, the dev branch sits there for 2-3 weeks gradually acquiring features (and people testing integration too, hopefully, with any fixes that emerge from that). But then you discover a bug in the currently live version, either from people using it or even from the integration work, and you want that fix live during the week (specific example: there's a rare but consistent CTD in a game mod, you do not want to leave that in for several weeks). Well, if you have a branch reflecting the live status you can put your hotfix there, do a release, and merge the hotfix into dev right away.
Speaking of game mods, that also gives you a situation where you have a hard dependency on another project - if they do a release in between your mods releases, you might need to drop a compat hotfix ASAP, and you want a reflection of the live code where you can do that, knowing you will always have a branch that works with the latest version of the game. If your main branch has multiple people's work on it, in progress, that differs from what's actually released, you're going to get a mess.
And sure you could do just feature branches and merge feature branches one by one into each other, and then into main so you never have code-under-integration in a centralized place but... why not just designate a branch to be the place to do integration work?
You could also merge features one by one into main branch but again, imagine the mod case, if the main code needs X update for compatibility with a game update, why do that update for every feature branch, and expect every contributor to do that work? Much better to merge a feature in when the feature is done, and if you're waiting on other features centralize the work to keep in step with main (and the dependency) in one place. Especially relevant if your feature contributors are volunteers who probably wouldn't have the time to keep up with changes if it takes a few weeks before they can merge in their code.
For the rest of us, trunk-based development with feature/fix branches is more than enough.
Of course, there are ways to enforce a known-good state on master without a dedicated develop branch, but it can be easier when having the two branches.
(I just dislike the name “develop”, because branch names should be nouns.)
I like the opportunity to force a second set of testing, and code review. Especially if the team is big enough that you can have different people doing code review for each branch.
You can also have your CI/CD do longer more thorough testing while merging to main vs development.
If it's a project with a single deployment, version tagging is kind of pointless, it's much easier to just use a branch to reflect what is live, and roll back to a merge commit if you have to. Then you can still merge directly to main in the event of a hotfix.
I never found this very compelling. What is main in that world is not the source of truth, and it's rare to have a system atomically in one state or the other - but normally there are progressive rollouts. And if you ever need to rollback in production, I assume no one is changing where main is.
> I like the opportunity to force a second set of testing, and code review. Especially if the team is big enough that you can have different people doing code review for each branch.
To be explicit for code review, do you mean there is (1) main, (1) development, and then a bunch feature branches - and that there is review when merging into development and main? Having a two-tiered review process seems extremely difficult to do - versus just having more reviewers on the first merge - especially dealing with merge conflicts and needing to merge again into development.
> You can also have your CI/CD do longer more thorough testing while merging to main vs development.
I think it's fair to do more testing later. I think the equivalent I'm used to (which is pretty close, so not a huge difference), is only building releases from the commit that passed the bigger/slower tests.
But also, assuming there are multiple deployments coming from one repo, if you block merging into main, that means you'd be blocking on all tests passing - while release branches for a given product can select a subset of tests when deciding on release candidates.
> If it's a project with a single deployment, version tagging is kind of pointless, it's much easier to just use a branch to reflect what is live, and roll back to a merge commit if you have to. Then you can still merge directly to main in the event of a hotfix.
I think it's worth maintaining the flexibility of how many releases come from a repo. Needing to fork repos just because you want another deployable release in the future seems painful to me.
In the scenarios I am thinking of, the only way to rollback production is to update the main branch and redeploy.
But still, it's just the niceness of having the default branch match production or the current release. Even if you're not going through the extra code review or testing, and all you did was automatically point main to the same commit as the latest release tag, it's still nice. Of course, you could have a production branch or whatever, set that as your default, and leave main for development, but the point is the same.
To be explicit for code review, do you mean there is (1) main, (1) development, and then a bunch feature branches - and that there is review when merging into development and main? Having a two-tiered review process seems extremely difficult to do - versus just having more reviewers on the first merge - especially dealing with merge conflicts and needing to merge again into development.
Yes, but merge conflicts are not an issue at all if you don't squash commits on merge, atleast not between development and main. The way we used to do it, was each part of the project had owners with one required to review all changes before merging to development, then any other senior developer could review the merge to main. Though, we would encourage the whole team to review every PR if they had time.
In practice, this was really just a chance to see all the changes going in on this next release.
I think it's worth maintaining the flexibility of how many releases come from a repo. Needing to fork repos just because you want another deployable release in the future seems painful to me.
When the development team is also the operations team it's easier to keep them together and just update the deployment to go to multiple places, which would effectively still be a single deployment.
If they're separate teams, then I would be inclined to give operations it's own repo where they can manage their specific things. With a pipeline that pulls down the artifacts from the development team.
I tried adhering to it at my first job but I guess I didn't understand git flow well enough because people just thought I was making random branches for fun.
> If this pattern is so pervasive, and so many people care enough to attempt to explain it to you, yet you remain unconvinced, I’m not sure how you reach the conclusion that you are right, and correct, and that it’s such a shame that the world does not conform to how you believe that things should be.
The reason nobody has convinced me otherwise isn't that I haven't listened, but because the people I talked to so far didn't actually have arguments to put forth. They seemed to be cargo-culting the model without thinking about why the branching strategy was what it was, and how that affected how they would work, or the effort that would be put into following each part of the model vs the value that this provides. It seemed to me that the main value of the model to them was that it freed them from having to think about these things. Which honestly, I have no problem with, we all need to choose where to put our focus. But also, all the more reason why I think it's worth caring about the quality of the patterns that these guys follow unquestioningly.
> Besides a bit of a puritan argument about “git gods”, you haven’t really justified why this matters at all, let alone why you care so much about it.
Apart from that (apparently failed) attempt at humor, I did in fact attempt to justify later in my comment why it matters: "instead of demoting the master/main branch to that role, when it already has a widely used, different meaning?" To expand on that, using the same names to describe the same things as others do has value - it lowers friction, allows newcomers (e.g. people used to the github branching model) to leverage their existing mental model and vernacular, and doesn't waste energy on re-mapping concepts. So when the use case for the master/main branch is already well-established, coming up with a different name for the branch you do those things on ("develop") and doing something completely different on the branch called master/main (tagging release commits), is just confusing things for no added benefit. On top of that, apart from how these two branches are named/used, I also argue that having a branch for the latter use case is mostly wasted effort. I'm not sure I understand why it needs to be spelled out that avoiding wasted effort (extra work, more complexity, more nodes in the diagram, more mental load, more things that can go wrong) in routine processes is something worth caring about.
> On the other hand, the model that you are so strongly against has a very easy to understand mental model that is analogous to real-world things. What do you think that the flow in git flow is referring to?
"very easy to understand mental model"s are good! I'm suggesting a simplification (getting rid of one branch, that doesn't serve much purpose), or at least using naming that corresponds with how these branches are named elsewhere, to make it even easier to understand.
You say it's a model that I'm "so strongly against". Have you actually read my entire comment? It says "Especially when the rest of it is so sensible - the whole feature-branch, release-branch, hotfix flow is IMO exactly right for versioned software". I'm not strongly against the model as a whole. I think 80% of it is spot on, and 20% of it is confusing/superfluous. I'm lamenting that they didn't get the last 20% right. I care exactly because it's mostly a good model, and that's why the flaws are a pity, since they keep it from being great.
As for "flow", I believe it refers to how code changes are made and propagated, (i.e. new feature work is first committed on feature branches, then merged onto develop, then branched off and stabilized on a release branch, then merged back to develop AND over onto master and tagged when a release happens). Why do you bring this up? My proposal is to simplify this flow to keep only the valuable parts (new feature work is first committed on feature branches, then merged onto master, then branched off and stabilized on a release branch, then tagged and merged back to master when a release happens). Functionally pretty much the same, there's just one less branch to manage, and develop is called master to match its naming elsewhere.
> I’m sorry that you find git flow so disgusting but I think your self-righteousness is completely unjustified.
Again, I don't know where you get this from. I don't find the model disgusting, I find it useful, but flawed. I don't know why you think suggesting these improvements justifies making remarks about my character.
A less rigid development branch allows feature branches to be smaller and easier to merge, and keeps developers working against more recent code.
A more locked-down, PR-only main branch enables proper testing before merging, and ensures that the feature and release branches stemming from it start in a cleaner state.
I've worked with both approaches and I'm firmly in the camp of keeping main stable, with a looser shared branch for the team to iterate on.
There's this. There's that video from Los Alamos discussed yesterday on HN, the one with a fake shot of some AI generated machinery. The image was purchased from Alamy Stock Photo. I recently saw a fake documentary about the famous GG-1 locomotive; the video had AI-generated images that looked wrong, despite GG-1 pictures being widely available. YouTube is creating fake images as thumbnails for videos now, and for industrial subjects they're not even close to the right thing. There's a glut of how-to videos with AI-generated voice giving totally wrong advice.
Then newer LLM training sets will pick up this stuff.
"The memes will continue" - White House press secretary after posting an altered shot of someone crying.
I clicked on one about Henry the 8th, which is a story Ive heard heard 100 times but whatever. It started out normal enough, then claimed he started carrying around a staff with a human skull on the top near the end. Made up artifacts and paintings.
The most egregious has to be the "World War II mechanic fixes entire allied plane arsenal with piece of wire" category. I've come across a couple dozen of these. Completely fabricated events and people that never seem to have existed.
I don't know what the current upload rate to YT is, but this seems unlikely. Despite the reckless and insane energy consumption associated with generative visual and audio art forms, there's no way there's enough power available for generative stuff to overwhelm the "actually recorded digital video" uploads.
Are there some niches on YT where this is true? Seems possible. YT overall? Nah.
Most of these kind of videos aren't fully SORA level AI anyway, they just use ChatGPT to make up a fake story and script they would otherwise have to make up themselves, which is much faster, and increases the chances one of them gets picked up by the algorithm and generates a few bucks in ad revenue.
Sure. But if you live in a multi-apartment complex and someone's toilet on the far side of the complex is overflowing, you don't say "my apartment is flowing with raw sewage".
Maybe your part of the complex (YT) is drowning in raw sewage, mine is not, and I'm vaguely confident that the complex (YT) is large enough that at this point in time, most parts of it are still functioning "as intended".
But YT shorts is the one place on YT that tries to frequently show you new uploads and stuff outside of your normal algorithm, and there is so much AI on there.
It wouldn’t happen to be a certain podcast about engineering disasters, now, would it?
Except when it was delivered, this one said "hug in a boy" and "with heaetfelt equqikathy" (whatever the hell that means). When we looked up the listing on Amazon it was clear it was actually wrong in the pictures, just well hidden with well placed objects in front of the mistakes. It seems like they ripped off another popular listing that had a similar font/contents/etc.
Luckily my cousin found it hilarious.
That this was ever published shows a supreme lack of care.
"What's dispiriting is the (lack of) process and care: take someone's carefully crafted work, run it through a machine to wash off the fingerprints, and ship it as your own. This isn't a case of being inspired by something and building on it. It's the opposite of that. It's taking something that worked and making it worse. Is there even a goal here beyond "generating content"?
The model makers attempt to add guardrails to prevent this but it's not perfect. It seems a lot of large AI models basically just copy the training data and add slight modifications
Copyright laundering is the fundamental purpose of LLMs, yes. It's why all the big companies are pushing it so much: they can finally freely ignore copyright law by laundering it through an AI.
This happens even to human artists who aren't trying to plagiarize - for example, guitarists often come up with a riff that turns out to be very close to one they heard years ago, even if it feels original to them in the moment.
Morge: when an AI agent is attempting to merge slop into your repo.
Do your part to keep GitHub from mutating into SourceMorge.
Or, alex_suzuki's colorful definition.
But really, whoever goes to Urban Dictionary first gets to decide what the word means. None of the prior definitions of "morg" has anything to do with tech.
brb, printing a t-shirt that says "continvoucly morged"
Resistance is futile.
I've been coding for over a decade, and I've built some great things, but the slow, careful, painstaking drudge-work parts were always the biggest motivation-killers. AI is worth it at any cost for removing the friction from these parts the way it has for me. Days of work are compressed into 20 minutes sometimes (e.g. convert a huge file of Mercurial hooks into Git hooks, knowing only a little about Mercurial hooks and none about Git hooks re: technical implementation). Donkey-work that would serve no value wasting my human time and energy on when a machine can do it, because it learned from decades of examples from the before-times when people did this by hand. If some people abuse the tools to make a morg here and there, so be it; it's infinitely worth the tradeoff.
(I don't entirely agree with him, but I upvoted for at least trying to get us back on topic!)
It's a perfectly cromulent word.
> looks like a vendor, and we have a group now doing a post-mortem trying to figure out how it happened. It'll be removed ASAFP
> Understood. Not trying to sweep under rugs, but I also want to point out that everything is moving very fast right now and there’s 300,000 people that work here, so there’s probably be a bunch of dumb stuff happening. There’s also probably a bunch of dumb stuff happening at other companies
> Sometimes it’s a big systemic problem and sometimes it’s just one person who screwed up
This excuse is hollow to me. In an organization of this size, it takes multiple people screwing up for a failure to reach the public, or at least it should. In either case -- no review process, or a failed review process -- the failure is definitionally systemic. If a single person can on their own whim publish not only plagiarised material, but material that is so obviously defective at a single glance that it should never see the light of day, that is in itself a failure of the system.
Then slow down.
With this objective lack or control, sooner or later your LLM experiments in production will drive into a wall instead of hitting a little pothole like this diagram.
- I can't, moving too fast!
Completely with you on this, plus I would add following thoughts:
I don't think the size of the company should automatically be a proxy measure for a certain level of quality. Surely you can have slobs prevailing in a company of any size.
However - this kind of mistake should not be happening in a valuable company. Microsoft is currently still priced as a very valuable company, even with the significant corrections post Satyas crazy CapEx commitments from 2 weeks ago.
However it seems recently the mistakes, errors and "vendors without guidelines" pile up a bit too much for a supposedly 3-4T USD worth company, culminating in this weird random but very educational case. If anything, it's indicator that Microsoft may not really be as valuable as it is currently still perceived.
It doesn’t.
The organization would have more guardrails in place if it prioritized "don't break things" over "move fast".
This is how it works. There are too many people here like the op that make assumptions on what the process is/should be.
That's not entirely unlike what you're doing here. You latched onto a misunderstanding of OP's intent, and by making a thing out of it got people to pull back, and now you also keep tugging on your end.
Except she does it on purpose and enjoys it, while I think you did it inadvertently and you do not seem that happy. But then, you're not a dog, of course.
You could stop pulling on the stick. I do enjoy these doggy similes, though. :)
p_ing, see my nearby comment about what we mean by "multiple". Does that comment make any false "assumptions"? Or, is it you who are mistaken, failing to understand what your interlocutors are saying?
It is extremely well-known that individual humans make mistakes. Therefore, any well-functioning system has guards in place to catch mistakes, such that it takes multiple people making mistakes for an individual mistake to cascade to system failure. A system that does not have these guards in place at all, and allows one individual's failure to immediately become a system failure, is a bad system, and management staff who implement bad systems are as responsible for their failure as the individual who made the mistake. Let us be grateful that you do not work in an engineering or aviation capacity, given the great lengths you are going to defend the "correctness" of a bad system.
There’s also a service that rates your grammar/clarity and you have to be above a certain score.
> that is in itself a failure of the system
... and add some Beer flavor: POSIWID (the purpose of a system is what it does)
I’ve lost trust in anything Microsoft publishes anymore.
Ortho and grammar errors should have been corrected, but do you really expect a review process to identify that a diagram is a copy from another one some rando already published on the internet years ago?
[0]: https://www.reuters.com/technology/microsoft-defend-customer...
I’ll never understand the implied projection.
(I don’t think this was reviewed closely if at all)
But even if you don't recognise the original, at least you should be able to tell that the generated copy is bullshit.
The original content is highly influential... which should be self-evident by the fact it is being reproduced verbatim ten years later, and was immediately recognized.
Here is the slop copy: https://web.archive.org/web/20251205141857/https://learn.mic...
The 'Time' axis points the wrong way, and is misspelled, using a non-existent letter - 'Tim' where the m has an extra hump.
It's pretty clear this wasn't reviewed at all.
We aren't talking about just some random image from some random blog. The article we are talking about is about a specific topic, which when searched online one of the first is the article containing the original image (at least for google, bing seems to be really struggling to give me the article but under images it is again the first).
I would cut some slack if this were a really obscure topic almost noone talks about, but it's been a thing talked about in the programmer space for ages.
(But the main issue is that the diagram is slop, not that it's a copy.)
Maybe we're of a different age to remember when Scott was super influential as a blogger / conference speaker, but even now he's not some random VP.
Now that's an interesting comment for him to include. The cynic in me could find / can think of lots of reasons from my YouTube feed as to why that might be so. What else is going on at Microsoft that could cause this sense of urgency?
Everybody's so worried about getting in on the ground floor of something that they don't even imagine it could be a massive flop.
For example, I know of an unrelated mandate Microsoft has for its management. Anything security team analysis flags in code that you or your team owns must be fixed or somehow acceptably mitigated within the deadline specified. It doesn't matter if it is Newton soft json being "vulnerable" and the entire system is only built for use by msft employees. If you let this deadline slip, you have to explain yourself and might lose your bonus.
Ok so the remediation for the Newton soft case is easy enough that it is worth doing but the point is I have a conspiracy theory that internally msft has such a memo (yes, beyond what is publicly disclosed) going to all managers saying they must adopt copilot, whatever copilot means.
Only if this is considered a failure.
Native English speakers may not know, but for a very long time (since before automatic translation tools became adequate) pretty much all MSFT docs were machine translated to the user agent language by default. Initially they were as useless as they were hilarious - a true slop before the term was invented.
They're chasing that sweet cost reduction by making cheap steel without regard for what it'll be used for in the future.
Vibing won’t help out at all, and years from now we’re gonna have project math on why 10x-LLM-ing mediocre devs on a busted project that’s behind schedule isn’t the play (like how adding more devs to a late project generally makes it more late). But it takes years for those failures to aggregate and spread up the stack.
I believe the vibing is highlighting the missteps from the wave right before which has been cloud-first, cloud-integrated, cloud-upselling that cannibalized MS’s core products, multiplied by the massive MS layoff waves. MS used to have a lot of devs that made a lot of culture who are simply gone. The weakened offerings, breakdown of vision, and platform enshittification have been obvious for a while. And then ChatGPT came.
Stock price reflects how attractive stocks are for stock purchasers on the stock market, not how good something is. MS has been doing great things for their stock price.
LLMs make getting into emacs and Linux and OSS and OCaml easier than ever. SteamOS is maturing. Windows Subsytem for Linux is a mature bridge. It’s a bold time for MS to be betting on brand loyalty and product love, even if their shit worked.
And that's exactly what happened here.
I have been having oodles of headaches dealing with exFAT not being journaled and having to engineer around it. It’s annoying because exFAT is basically the only filesystem used on SD cards since it’s basically the only filesystem that’s compatible with everything.
It feels like everything Microsoft does is like that though; superficially fine until you get into the details of it and it’s actually broken, but you have to put up with it because it’s used everywhere.
Nope.
TFA writes this: "The AI rip-off was not just ugly. It was careless, blatantly amateuristic, and lacking any ambition, to put it gently. Microsoft unworthy".
But I disagree: it's classic Microsoft.
> I have been having oodles of headaches dealing with exFAT not being journaled and having to engineer around it. It’s annoying because exFAT is basically the only filesystem used on SD cards since it’s basically the only filesystem that’s compatible with everything.
I hear you. exFAT works on Mac, Linux and Windows. I use it too, when forced. Note that bad old vfat also still works everywhere
It's not like LinkedIn was great before, but the business-influencer incentives there seem to have really juiced nonsense content that all feels gratingly similar. Probably doesn't help that I work in energy which in this moment has attracted a tremendous number of hangers-on looking for a hit from the data center money funnel.
https://www.marginalia.nu/junk/linked/games.jpeg
https://www.marginalia.nu/junk/linked/json.png
https://www.marginalia.nu/junk/linked/syntax.png
(and before anyone tells me to charge my phone, I have one of those construction worker phones with 2 weeks battery. 14% is like good for a couple of days)
Regardless, FP-style code isn’t “shiny new stuff”—it’s been around for decades in languages like Lisp or Haskell. Functional programming is just as theoretically “fundamental” as imperative programming. (Not to mention that, these days, not even C corresponds that closely to what’s actually going on in hardware.)
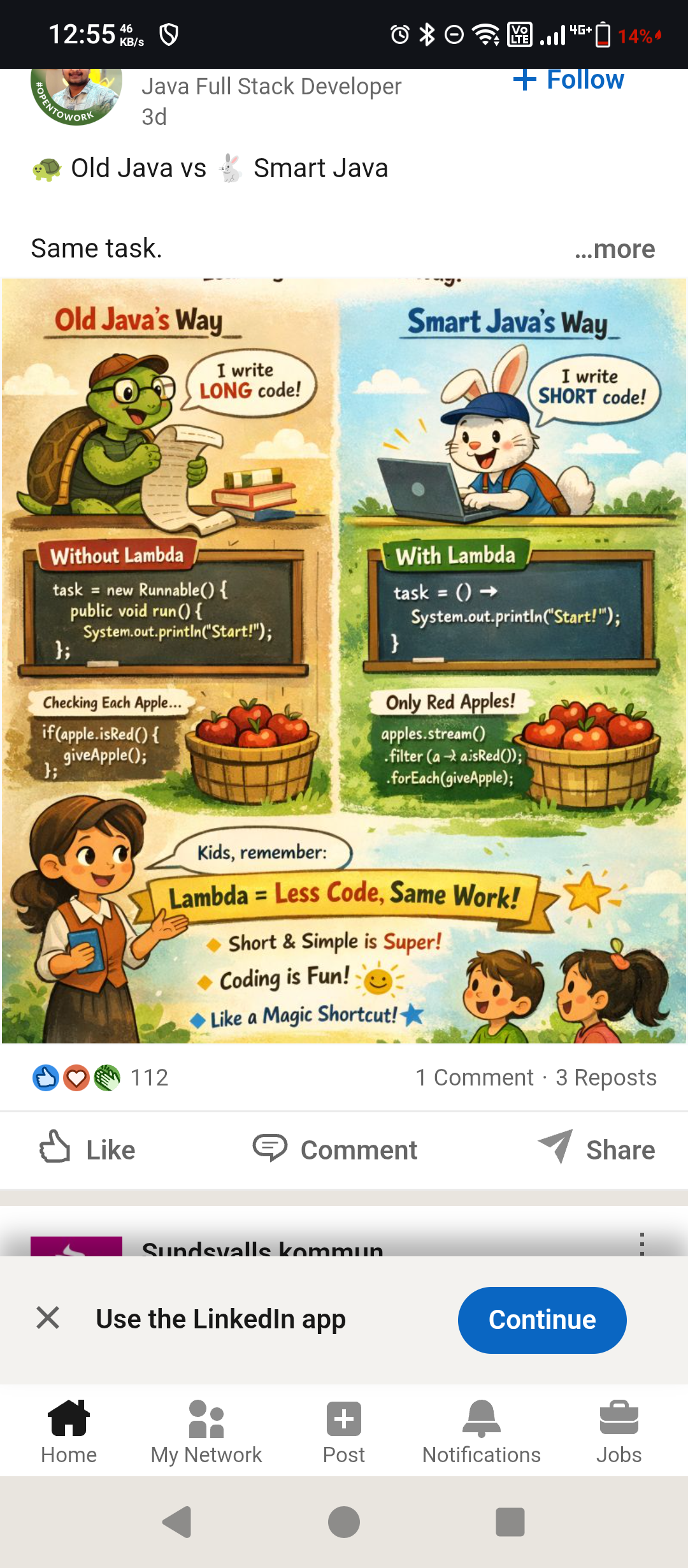
>> .filter (a -} ajsRed());
>> .forEach(giveApple); [sic]
> The red apple streams one is good. It shows how developers chase shiny new stuff with no respect for fundamentals.
The problem isn’t streams, it’s slop.
Lambda example is to the best of my parsing ability this:
apples.stream()
.filter(a -λ a.isRed()); // <-- note semicolon
.forEach(giveApple);
apples.stream()
.filter(a -> a.isRed()) // or Apple::isRed
.forEach(a -> giveApple(a)); // or this::giveApple
- missing ")" on the left side
- extra "}" on the right side
- the apples example on the right side ("Short code") ist significantly longer than the equivalent "Long code" example on the left side (which might also be because that code example omits the necessary for loop).
- The headings don't provide structure. "Checking Each Apple" and "Only Red Apples!" sounds like opposites, but the code does more or less the same in both cases.
Not mentioning the pain of debugging the streaming solution is also a little disingenuous.
that one gave me an actual lol.
I wish I could say I’m making bank off this strategy - but pretty-much all the slopposters (and the most insufferable of the AI boosters) are all working for nonpublic firms, oh well.
I use block option there quite a lot. That cleans up my experience rather well.
Daniel Stenberg Jason Fried David Heinemeier Hansson Nick Chapsas Laurie Kirk Brian Krebs
That's the main trait of almost all social media. A parade of falsity, putting on the show for everyone else, being what you wish you were and what everyone else dreams of being or envies.
LinkedIn is about boasting and boosting the professional life, other social media is for the personal life. More or less equally fake.
I'm surprised they are able to care so little. Somebody actually published this and didn't care enough to even skim through it.
The people who got Cs in your English class are functionally illiterate.
IMO Microsoft is right at the nexus of opportunity for solving some of the the large _problems_ that AI introduces.
Employers and job seekers both need a way to verify that they are talking to real identified people that are willing to put in some effort beyond spamming AI or wasting your time on AI run filters. LinkedIn could help them.
Programmers need access to real human-verified code and projects they can trust, not low-effort slop that could be backdoored at any moment by people with unclear motives and provenance. Github could help.
etc. etc. for Office, Outlook ...
But instead they've decided to ride the slop waves, throw QA to the wind, and call every bird and stone "copilot".
> At Microsoft, we're working to add articles to Microsoft Learn that contain AI-generated content. Over time, more articles will feature AI-generated text and code samples.
From: https://learn.microsoft.com/en-us/principles-for-ai-generate...
<vomit emoji here>
A few weeks ago, I needed some syntax information to help with building out a PowerShell script. The input and output parameter sections each included "{{ Fill in the Description }}"[1] in lieu of any meaningful content. There wasn't even a link to the data type's description elsewhere in the Learn database. I was ultimately able to get done what I needed to do, but it really irked me that whoever developed the article would publish it with such a glaring omission.
[1] https://learn.microsoft.com/en-us/powershell/module/microsof...
Morg doesn't seem to be a word in English (though it is in Irish!), but it sounds like it should be.
This is one aspect of AI I will miss, if we ever figure out how to make it go away. The delightful chaos. It invented a word here, without even meaning to.
For example, I vibe coded a QWOP clone the other day, and instead of working human legs, it gave me helicopter legs. You can't walk, but if you mash the keyboard, your legs function as a helicopter and you can fly through the sky.
That obviously wasn't intentional! But it was wonderful. I fear that in a few years, AI will be good enough to give me legs that don't fly like a helicopter. I think we will have lost something special at that point.
When I program manually, I am very good at programming bugs. If I'm trying to make something reliable, that's terrible. But if I'm trying to make a computer do something nobody even realized it can do... making it do things you weren't expecting is the only reliable way to do that.
So I've been working on a way to reintroduce bugs mechanically, by mutating the AST. The fundamental idea is sound -- most of my bugs come from "stuff I obviously meant to type, but didn't" -- but it needs a bit more work. Right now it just produces nonsense even I wouldn't come up with :)
I currently have "mess up the file". The next 2 phases would be "in a way so that it still compiles", and "in a way so that it doesn't (immediately) crash at runtime", (since the whole point is "it still runs, but it does something weird!"). More research needed :)
Maybe because English also has 'morgue'.
Or to put it more bluntly.. can we get correctness without cringe ;)
I think it could be done, to a degree, with current systems, but it would be more expensive. You'd increase the temperature, and then you'd do more runs. And you could do that iteratively... re-generate each paragraph a few times, take the best of N. So you end up with interesting output, which still meets some threshold of quality.
Actually that doesn't sound too hard to slap together right now...
We should start calling this "copyright laundering".
It took me a few times to see the morged version actually says tiന്ന
$ python -c 'print(list(map(__import__("unicodedata").name, "ന്ന")))'
['MALAYALAM LETTER NA', 'MALAYALAM SIGN VIRAMA', 'MALAYALAM LETTER NA']
$ pyp 'map(unicodedata.name, "ന്ന")'
MALAYALAM LETTER NA
MALAYALAM SIGN VIRAMA
MALAYALAM LETTER NASo these services depends on journalists to continuously feed them articles, while stealing all of the viewers by automatically copying every article.
I honestly don't get it. All I want is for it to quote verbatim and link to the source. This isn't hard, and there is no way the engineers at Google don't know how to write a thesis with citations. How did things end up this way?
It is not a carefully designed product; ask yourself "What is it FOR?".
But the identification of reliable sources isn't as easy as you may think, either. A chat-based interaction really makes most sense if you can rely on every answer, otherwise the user is misled and user and conversation may go in a wrong direction. The previous search paradigm ("ten snippets + links") did not project the confidence that turns out is not grounded in truth that the chat paradigm does.
This is obviously a big, unanswered, issue. It's pretty clear to me that we are collectively incentivised to pollute the well, and that it happens for long-enough for everything to become "compromised". That's essentially abandoning opensource and IP licensing at large, taking us to an unchartered era where intellectual works become the protected property of nobody.
I see chatbots having less an impact on our societies than the above, and interestingly it has little to do with technology.
Microsoft just spits in this creator's face by mutilating his creation in a bad way.
"Its not this its that" is the new em-dash.
This is the part that hurts. It's all so pointless, so perfunctory. A web of incentives run amok. Systems too slick to stop moving. Is this what living inside the paperclip maximizer feels like?
Words we didn't write, thoughts we didn't have, for engagement, for a media presence, for an audience you can peddle yourself to when your bullshit job gets automated. All of that technology, all those resources, and we use it to drown humanity in noise.
It took ~5 months for anyone to notice and fix something that is obviously wrong at a glance.
How many people saw that page, skimmed it, and thought “good enough”? That feels like a pretty honest reflection of the state of knowledge work right now. Everyone is running at a velocity where quality, craft and care are optional luxuries. Authors don’t have time to write properly, reviewers don’t have time to review properly, and readers don’t have time to read properly.
So we end up shipping documentation that nobody really reads and nobody really owns. The process says “published”, so it’s done.
AI didn’t create this, it just dramatically lowers the cost of producing text and images that look plausible enough to pass a quick skim. If anything it makes the underlying problem worse: more content, less attention, less understanding.
It was already possible to cargo-cult GitFlow by copying the diagram without reading the context. Now we’re cargo-culting diagrams that were generated without understanding in the first place.
If the reality is that we’re too busy to write, review, or read properly, what is the actual function of this documentation beyond being checkbox output?
And there ist another website with the same content (including the sloppy diagram). I had assumed that they just plagiarized the MS tutorials. Maybe the vendor who did the MS tutorial just plagiarized (or re-published) this one?:
https://techhub.saworks.io/docs/intermediate-github-tutorial...
> So we end up shipping documentation that nobody really reads
I'd note that the documentation may have been read and noticed as flawed, but some random person noticing that it's flawed is just going to sigh, shake their heads, and move on. I've certainly been frustrated by inadequate documentation before (that describes the majority of all documentation, in my experience), but I don't make a point of raising a fuss about it because I'm busy trying to figure out how to actually accomplish the goal for which I was reading documentation for rather than stopping what I'm doing to make a complaint about how bad the documentation is.
This says nothing to absolve everyone involved in publishing it, of course. The craft of software engineering is indeed in a very sorry state, and this offers just one tiny glimpse into the flimsiness of the house of cards.
> people started tagging me on Bluesky and Hacker News
Never knew tagging was a thing on Hacker News. Is it a special feature for crème de crème users?
It's a very very hard and time consuming task for dev to maintain hotfix for previous releases !
Yeah, easier for users, they don't have to care about breaking changes or migration guide. They just blindly update to the nearest minor.
But as the time goes on, the code for dev ends up being a complete mess of git branches and backports. Dev finally forgot some patches and the software contains a major security hole.
Dev ends by being exhausted, frustrated by its project and roasted by its users.
=> What I do : do not maintain any previous release but provide a strong migration guide and list all breaking changes !
users just have to follow updates or use another software.
I'm happy with it, my project has no debt code and more clean code.
I have seen firsthand how the original git-flow post convinced management to move off SVN. In that regard, it's an extremely important work. I've also never seen git-flow implemented exactly as described.
...and frankly, there are better ways to use git anyway. The best git workflows I've seen, at small scale and large, have always been rebase-only.
I sometimes ask Claude to read some code and generate a process diagram of it, and it works surprisingly well!
An LLM driving mermaid with text tokens will produce infinitely more accurate diagrams than something operating in raster space.
A lot of the hate being generated seems due to really poor application of the technology. Not evil intent or incapable technology. Bad engineering. Not understanding when to use png vs jpeg. That kind of thing.
But man this one indicates such a horrible look / lack of effort (like none) from Microsoft.
Not that Microsoft is short on bad looks, but this really seems like one of those painfully symbolic ones.
https://web.archive.org/web/20250908220945/https://learn.mic...
> the diagram was both well-known enough and obviously AI-slop-y enough that it was easy to spot as plagiarism. But we all know there will just be more and more content like this that isn't so well-known or soon will get mutated or disguised in more advanced ways that this plagiarism no longer will be recognizable as such.
Most content will be less known and the ensloppified version more obfuscated... the author is lucky to have such an obvious association. Curious to see if MSFT will react in any meaningful way to this.
Edit: typo
Please everyone: spell 'enslopified', with two 'p's - ensloppiified.
Signed, Minority Report Pedant
I don’t even care about AI or not here. That’s like copying someone’s work, badly, and either not understanding or not giving a shit that it’s wrong? I’m not sure which of those two is worse.
Seems to be perfectly on brand for Microsoft, I don’t see the issue.
so standard Microslop
I'd argue that this statement is perfectly true when the word "unworthy" is removed.
These people distilled the knowledge of AppGet's developer to create the same thing from scratch and "Thank(!)" him for being that naive.
Edit: Yes, after experiencing Microsoft for 20+ odd years, I don't trust them.
At some point, AI transformations of our work is just good enough but not excellent enough. And that is where the creators’ value lies.
EDIT: Worse than I thought! Who in their right mind uses AI to generate technical diagrams? SMDH!
"Don't attribute to malice what can be adequately explained by stupidity". I bet someone just typed into ChatGPT/Copilot, "generate a Git flow diagram," and it searched the web, found your image, and decided to recreate it by using as a reference (there's probably something in the reasoning traces like, "I found a relevant image, but the user specifically asked me to generate one, so I'll create my own version now.") The person creating the documentation didn't bother to check...
Or maybe the image was already in the weights.
well, what should i say...
I can't find a link to the learn page so can only see what's on the article. Is this a real big deal? Genuine question, driveby downvote if you must.
Even if this was a product of AI surely it's just a case of fessing up and citing the source? Yeah it doesn't look good for MS but it's hardly the end of the world considering how much shit AI has ripped off... I might be missing something.
lmao where has the author been?! this has been the quintessential Microsoft experience since windows 7, or maybe even XP...
Edit: Apparently you didn't.
Ref: https://www.reddit.com/r/technology/comments/1r1tphx/microso...
That pretty much describes Microsoft and all they do. Money can't buy taste.
He was right:
LOL, I disagree. It's very on brand for Microslop.
A noun describing such piece of slop could be „morgery”.
Seconded!
On the other hand, it makes sense for Microsoft to rip this off, as part of the continuing enshittification of, well, everything.
Having been subjected to GitFlow at a previous employer, after having already done git for years and version control for decades, I can say that GitFlow is... not good.
And, I'm not the only one who feels this way.
The author of the Microsoft article most likely failed to credit or link back to his original diagram because they had no idea it existed.
If this has been discovered once, it must be happening every day. What can we do about that? Perhaps image generators need to build in something like a Tineye search to validate the novelty of their output before returning it.
This is just another reminder that powerful global entities are composed of lazy, bored individuals. It’s a wonder we get anything done.
Is it about the haphazardous deployment of AI generated content without revising/proof reading the output?
Or is it about using some graphs without attributing their authors?
if it's the latter (even if partially) then I have to disagree with that angle. A very widespread model isn't owned by anyone surely, I don't have to reference newton everytime I write an article on gravity no? but maybe I'm misunderstanding the angle the author is coming from
(Sidenote: if it was meant in a lightheaded way then I can see it making sense)
not at all about the reuse. it's been done over and over with this diagram. it's about the careless copying that destroyed the quality. nothing was wrong with the original diagram! why run it through the AI at all?
I mean come on – the point literally could not be more clearly expressed.
> In 2010, I wrote A successful Git branching model and created a diagram to go with it. I designed that diagram in Apple Keynote, at the time obsessing over the colors, the curves, and the layout until it clearly communicated how branches relate to each other over time. I also published the source file so others could build on it.
If you mean that the Microsoft publisher shouldn't be faulted for assuming it would be okay to reproduce the diagram... then said publisher should have actually reproduced the diagram instead of morging it.
what's the bet that the intention here was explicitly to attempt to strip the copyright
so it could be shoved on the corporate website without paying anyone
(the only actual real use of LLMs)
See also: Copilot.
{kind=link}
{kind=link}
{kind=link}
{kind=link}